RAG is Hard Until I Know these 12 Techniques → RAG Pipeline to 99% Accuracy
RAG is Hard Until I Know these 12 Techniques → RAG Pipeline to 99% Accuracy. Best Blog to Scale or increase RAG Pipelines Accuracy.
medium.com
본 포스트는 왜 RAG가 어려웠는지, 왜 성능이 좋지 않았는지를 이야기하면서
RAG를 활용한 LLM 서비스 성능을 높일 수 있는 여러 방안을 제시하고 있다.
가장 기본적인 RAG는 성능이 좋지 않다는 것은 LLM 개발자라면 다 알 것이다.
나도 본 포스트에 나와있는 몇가지 방안들을 접목을 하고 있는데, 해보지 않은 것들도 보여서 정리를 해보고자 한다!
📌 Contents
1. 왜 기본적인 RAG는 실패하는가
2. 고성능 RAG를 위한 12가지 핵심 기법
3. 성과를 측정하는 올바른 지표
4. 추가적인 고급 기법들
5. 결론 및 실행 권장
기본적인 RAG는 왜 실패할까?
RAG(Retrieval-Augmented Generation)의 기본 파이프라인은 다음과 같다 :
Chunking (문서 쪼개기) → 임베딩 → 벡터DB 저장 → 유사도 기반 top-k 문서 검색

하지만 이는 실제 현업에서 잘 작동하지 않는다. 왜일까?
🔹 1. 복합적인 쿼리 처리의 한계
답변을 위해 여러 chunk의 정보를 종합적 추론해야 하는 경우, 단순 유사도 검색은 쉽게 실패한다.
🔹 2. 문맥 파손 (Context Fragmentation)
문서를 일정 길이로 잘라 chunking하면, 문맥이 인위적으로 끊기게 된다 → LLM이 핵심 흐름을 놓칠 수 있다.
🔹 3. 애매하거나 복잡한 질문 처리 실패
질문 자체가 모호하거나 복수의 의미를 담고 있을 때, 잘못된 chunk를 검색하게 되어 LLM이 엉뚱한 추론을 하게 된다.
🔹 4. 다중 소스 정보 통합 불가
다양한 문서, 출처에서 정보를 가져와야 하는 경우, 단순 벡터 검색은 서로 다른 문서 간 연관성을 잘 처리하지 못한다.
정확도 높은 RAG 시스템을 만들기 위해서는, 단순 검색 그 이상을 알아야 한다.
→ 검색(Retrieval), 정렬(Ranking), 추론(Reasoning)에 대한 기술이 핵심이다.
고성능 RAG를 위한 핵심 기법
RAG 시스템의 성능은 LLM 크기에 달려 있다고 생각할 수 있지만, 정확도를 99%까지 끌어올린 비결은 정보를 어떻게 검색하고 정리하느냐에 달려 있다. 이제 그 방법들을 차례대로 알아보자!

📍 PageIndex : 문서를 사람처럼 탐색하기
기존 RAG는 문서를 작게 쪼개서 벡터화하지만, PageIndex는 전혀 다르다.
문서 전체를 계층적 트리 구조로 인덱싱하고, LLM이 마치 보고서를 스킴 리딩하듯 구조적으로 탐색할 수 있게 만든다.
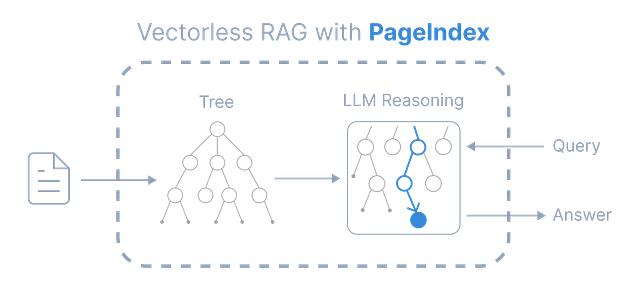
왜 효과적일까?
🔹 문맥 유지 : 인위적인 chunk 없이 원래 문서 구조를 그대로 반영
🔹 구간 기반 추론 : LLM이 전체 섹션 단위로 reasoning 수행
🔹 투명성 : 어떤 섹션이 사용됐는지 추적 가능
🔹 정확도 향상 : 복잡한 데이터셋에서 정확도 40% 이상 향상
🔻 실제 성능
- 일반 벡터 검색 기반 RAG : 50% 정확도
- PageIndex 기반 RAG : 98.7% 정확도
🔻 단점
▫️ 복잡성 : 트리 구조 구축과 유지가 어렵고 리소스를 많이 사용함
▫️ 속도 : 트리 기반 추론은 단순 벡터 검색보다 느릴 수 있음
🔻 예시 코드
from langchain.indexes import PageIndex
from langchain.llms import OpenAI
#재무 보고서를 트리 인덱스로 구축
document_tree = PageIndex.from_documents(documents)
#질의 수행
llm = OpenAI(temperature=0)
query = '2분기 순이익 추이는 어땠나요?'
response = document_tree.query(query, llm=llm)
print(repsonse)
📍 Multivector Retrieval : 다각도로 검색하기
기존 방식은 chunk마다 하나의 임베딩만 생성하지만,
Multivector Retrieval은 여러 개의 임베딩을 만들어 다양한 관점에서 정보를 검색한다.
예를 들어,
▪️ 전체 본문 임베딩
▪️ 요약 임베딩
▪️ 키워드 임베딩
▪️ 예상 질문 임베딩
왜 효과적일까?
🔹 다양한 질문 유형 대응 : 하나의 임베딩으로는 모든 의미를 담기 어렵다.
🔹 다중 임베딩은 쿼리의 다양한 해석 방향을 커버할 수 있어, 복잡한 질문에도 적중률이 높아진다.
🔻 단점
▫️ 저장 비용 증가 : chunk당 여러 개의 벡터를 저장하므로, 스토리지 사용량이 증가
▫️ 인덱싱 복잡도 증가 : 사전처리와 색인 구축 시간이 오래 걸림
🔻 예시 코드
from langchain.vectorstores import FAISS
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
#하나의 chunk에 대해 여러 임베딩 생성
embeddings = [
model.encode(chunk.text), #본문
model.encode(chunk.summary), #요약
model.encode(chunk.keywords) #키워드
]
faiss_index = FAISS.from_embeddings(embeddings)
📍 Metadata Augmentation : 메타데이터 보강
단순히 텍스트만 벡터화하는 대신, 각 chunk에 추가적인 메타데이터를 붙여주는 방식이다
예. 출처, 작성자, 작성일, 신뢰도 점수, 관련 엔티티 등
왜 효과적일까?
🔹 검색 정밀도 향상 : 단순 벡터 유사도 검색보다 더 정확한 결과 제공
🔹 신뢰도 확보 : 출처, 작성자, 날짜 정보를 활용해 LLM이 신뢰할 수 있는 근거를 우선시
🔹 임용 품질 개선 : 출처 기반 답변으로 정확한 citation 가능
🔻 단점
▫️ 수작업 부담 : 메타데이터 수집 및 정제가 사람 손을 많이 탈 수 있음
▫️ 품질 의존성 : 메타데이터의 품질이 낮으면, 검색 품질도 저하됨
🔻 예시코드
chunk = {
"text": "Company A reported a 10% increase in revenue.",
"source": "Quarterly Report 2025",
"author": "Finance Dept.",
"entities": ["Company A", "Revenue"],
"quality_score": 0.95
}
vectorstore.add_texts([chunk["text"]], metadatas=[chunk])
📍 CAG (Cache-Augmented Generation) : 캐시 기반 생성
CAG는 자주 사용되는 정적 데이터(ex.규정집, 메뉴얼, 가이드라인)를 모델의 KV 캐시에 미리 적재해두는 방식이다.
쿼리가 들어올 때마다 전체 RAG 파이프라인을 돌릴 필요 없이, 캐시에서 즉시 응답한다.
왜 효과적일까?
🔹 응답 속도 향상 : 자주 묻는 질문(FAQ) 처리 속도가 50~70% 단축
🔹 비용 절감 : 동일한 정적 데이터를 반복 검색하지 않아, 계산 리소스 절약
🔹 RAG와 시너지
- RAG → 최신/동적 데이터 처리
- CAG → 정적/반복적 데이터 처리
🔻 단점
▫️확장성 한계 : 캐시는 코빈도, 정적 데이터에만 유용. 새로운 동적 정보에는 불리
▫️메모리 사용량 : KV 캐시에 데이터를 미리 올려두므로, 메모리 시소스 소모 큼
🔻 예시코드
#정적 문서를 KV 캐시에 미리 적재
kv_cache = CAGCache()
kv_cache.preload(static_documents)
#쿼리 시 캐시를 활용해 응답
response = llm.generate(query, context=kv_cache)
실제 기업들에서 CAG를 도입해 고빈도 질의 응답 속도를 50~70% 개선했다고 보고함
📍 Contextual Retrieval : 문맥 강화 검색
단순한 chunk 텍스트만 임베딩하지 않고, 추가적인 문맥(context)을 함께 포함해 벡터화하는 방식이다.
Anthropic의 연구에서 영감을 받은 기법으로, 쪼개진 텍스트가 의미를 잃지 않도록 돕는다.
왜 효과적일까?
🔹 검색 정확도 개선 : 독립된 chunk가 가진 의미 손실 방지
🔹 효율성 향상 : 애매하거나 복잡한 질문에서도 처음부터 올바른 정보를 검색 가능
🔹 성능 수치 : 단독 사용 시 정확도 ~49% 개선, reranking과 결합 시 최대 67% 개선
🔻 단점
▫️ 추가 지연(latency) : 임베딩 전 context를 붙이는 과정에서 약간의 지연 발생
▫️ 프롬프트 설계 의존성 : 유용한 문맥을 얼마나 잘 붙이느냐가 효과를 좌우
🔻 예시코드
def contextualize(chunk):
#임베딩 전에 문맥을 추가
return f"In the 2022 finance report, {chunk['test']}'
emeddings = model.encode([contextualize(c) for c in chunks])
📍 Reranking : 검색 결과 재정렬
단순 유사도 검색 후, 재정렬 모델을 사용해 진짜 관련성을 기준으로 순서를 다시 매긴다.
LLM이 가장 신뢰할 수 있는 근거를 더 보도록 하는 단계다.
하지만 논문 상으로는 가장 앞과 가장 뒤의 문서를 llm이 많이 검색 한다고 한다
왜 효과적일까?
🔹 검색 품질 향상 : '관련 있을지도' 단계에서 '매우 관련 있음' 수준으로 격상
🔹 정확한 추론 보장 : LLM이 불필요한 문서 대신, 최적의 증거만 보고 reasoning 가능
🔹 성능 수치 : 단순 유사도 검색 대비 정확도 최대 60% 개선
🔻 단점
▫️ 추가 지연 : 두 번째 모델을 실행해야 하므로 latency 증가
▫️ 비용 증가 : 더 정교한 reranker 모델을 사용할수록 비용이 커짐
🔻 예시코드
from transformers import AutoModelForSequenceClassification, AutoTokenizer
#reranker 모델 로드
tokenizer = AutoTokenizer.from_pretrained("cross-encoder/ms-marco-MiniLM-L-6-v2")
model = AutoModelForSequenceClassification.from_pretrained("cross-encoder/ms-marco-MiniLM-L-6-v2")
def rerank(query, candidates):
inputs = toeknizer([query]*len(candidates), candidates, return_tensors='pt', padding=True)
scores = model(**inputs).logits.squeeze().detach().numpy()
ranked = [c for _, c in sorted(zip(scores, candidates), reverse=True)]
return ranked
# Q2 2025 순이익 추이 관련 문서 재정렬
top_candidates = rerank('Net profit trend Q2 2025', retrieved_docs)
📍 Hybrid RAG : 하이브리드 검색
벡터 기반 의미 검색과 그래프 탐색을 결합하는 방식으로, 멀티홉 추론이 필요한 복잡한 질문 처리에 적합하다.
- 벡터 검색: 의미적으로 유사한 정보를 찾음
- 그래프 탐색: 엔티티 관계·의존성을 추적
왜 효과적일까?
🔹 벡터 검색 → 문맥적으로 유사한, 의미적으로 유사한 정보 확보하는 데 유용
🔹 그래프 탐색 → 관계 기반 reasoning에 최적화
🔹 두 가지 방식을 결합하면 단순/복잡 질의 모두 효과적으로 대응 가능
🔻 단점
▫️ 구현 복잡성: 벡터 + 그래프 시스템을 통합 관리해야 함
▫️ 인프라 비용 증가: 두 가지 검색 방식을 동시에 운영해야 함
🔻 예시 코드
# vector retrieval
vector_candidates = vectorstore.similarity_search(query)
# graph retrieval
graph_candidates = knowledge
📍 Self-Reasoning : 자체 추론 검증
RAG를 단순히 '검색 후 전달'하는 수동적 구조에서 , 스스로 검증·평가하는 단계들을 추가함으로써,
LLM을 단순 검색기가 아닌 능동적 에이전트로 바꾼다.
- RAP(Relevance-Aware Process) : 검색 결과의 관련성 평가
- EAP(Evidence-Aware Process) : 근거 문장을 선택하고 정당화
- TAP(Trajectory Analysis Process) : 추론 경로를 통합해 최종 답변 생성
왜 효과적일까?
🔹 LLM이 스스로 오류 수정 및 검색 정제 가능, 잘못된 chunk를 걸러내고 정확한 근거를 유지
🔹 환각(hallucination) 감소
🔹 인용 정확도 향상
🔹 정확도: 표준 RAG 72.1% → Self-Reasoning 83.9%
🔻 단점
▫️ 속도 저하: 다단계 reasoning으로 계산량↑
▫️ LLM 의존성: LLM의 추론 능력에 따라 성능 차이 큼
🔻 예시 코드
for chunk in retrieved_chunks:
relevance_score = llm.evaluate_relevance(chunk, query)
if relevance_score > 0.7:
evidence_chunks.append(chunk)
answer = llm.synthesize_answer(evidence_chunks)
📍 Iterative / Adaptive RAG : 반복·적응형 RAG
쿼리 난이도에 따라 검색 전략을 달리하는 방식이다.
모든 쿼리에 동일학 방식(one-size-fits-all)을 적용하지 않고, 질문의 성격에 맞춰 전략을 달리해 효율적이고 유연한 시스템을 만든다.
- 단순 쿼리 → 1단계 검색
- 복잡 쿼리 → 다단계 반복 검색
왜 효과적일까?
🔹 효율성 향상 : 단순 질문엔 빠르고 가볍게 처리해 시간, 비용 절약
🔹 철저함 보장 : 복잡 질문엔 반복 검색을 적용해 누락 없이 정밀한 답변 제공
🔹 자원 최적화: 필요할 때만 연산 자원을 집중 투입
🔻 단점
▫️ 라우팅 로직 복잡 → 쿼리 난이도를 분류하는 로직을 세밀하게 구현해야 함
▫️ 개발·테스트 비용 증가 : 복수의 검색 경로를 지원하기 때문에 개발, 테스트 시간이 늘어남
🔻 예시 코드
complexity = query_classifier.predict(query)
if complexity == 'simple' :
answer = simple_retrieve(query)
else:
answer = iterative_retrieve(query)
이렇게 하면 효율적이고 반응성이 뛰어난 시스템을 만들 수 있다.
단순 질의는 시간, 자원 절약, 복잡 질의는 철저한 대응을 할 수 있다!
📍 Graph RAG : 지식 네트워크 구축
문서에서 엔티티·개념·사실을 추출해 지식 그래프로 변환하여 엔티티, 개념, 사실 간의 관계를 연결한다.
왜 효과적일까?
🔹 멀티홉 reasoning에 최적화
🔹 관계 기반 추론으로 환각 최소화
🔹 복잡한 관계형 질의에 강력
🔻 단점
▫️ 구축 비용 : 그래프 구축·유지 비용 큼
▫️ 확장성 문제 : 대규모 문서 확장 시 성능 저하 우려
🔻 예시 코드
from langchain.graphs import KnowledgeGraph
kg = KnowledgeGraph()
kg.add_entities_from_documents(documents)
kg.add_edges_from_relationships(relationships)
# Query graph for relevant context
related_entities = kg.query_entities("Company A", depth=2)
📍 Query Rewriting : 쿼리 재작성
사용자의 모호하거나 불완전한 질문을 검색 가능한 형식으로 변환한다.
- 모호성 해소
- 복잡한 질문 → 서브쿼리 분리
- 도메인 컨텍스트 추가
왜 효과적일까?
🔹 애매한 입력도 검색 성공률↑
🔹 사용자 경험 개선 : 검색 성공률과 사용자 경험 모두 향상
🔻 단점
▫️ LLM이 의도를 잘못 해석하면 잘못된 결과가 발생
▫️ 추가 지연 : 검색 전 단계가 하나 더 들어감
🔻 예시 코드
def rewrite_query(raw_query):
# 모호성 해소 + 컨텍스트 추가
return f"In the 2025 finance report, {raw_query}"
clean_query = rewrite_query("Net profit Q2")
📍 BM25 Integration : 키워드 기반 + 벡터 기반 통합 - Hybrid Search
BM25 키워드 검색과 벡터 기반 의미 검색을 병렬로 수행한 뒤, 가중치 점수를 합산해 최적 후보를 선정한다.
왜 효과적일까?
🔹 벡터 검색 → 의미적 유사성 반영
🔹 BM25 → 정확한 키워드/코드 매칭
🔹 두 방식을 결합해 더 정밀한 검색 결과 제공
🔻 단점
▫️ 가중치 튜닝 필요 (결합 비율 조정이 까다로움)
▫️ BM25 단독으론 의미 이해 부족
🔻 예시 코드
from rank_bm25 import BM25Okapi
bm25 = BM25Okapi([doc.split() for doc in docs])
bm25_scores = bm25.get_scores(query.split())
# Combine BM25 + semantic vector scores
final_scores = 0.6 * vector_scores + 0.4 * bm25_scores
ranked_docs = [doc for _, doc in sorted(zip(final_scores, docs), reverse=True)]
📌 Knowledge Graph와 RAG : 다양한 접근법과 한계
📍 LLM-Heavy Extraction (LLM 중심 추출)
가장 흔한 방식은 LLM에 직접 그래프 트리플 생성을 요청하는 것이다.
LangChain의 LLMGraphTransformer가 대표적이다.
왜 효과적일까?
🔹 LLM이 다양한 패턴을 이해해 (주어, 관계, 목적어) 트리플을 자동 생성
🔹 Schema prompt를 함께 사용하면 일관성 확보 가능
🔻 단점
▫️ 대규모, 다양한 도메인(법률, 연구 논문, 고객 데이터 등)에선 모든 노드, 관계를 사정 정의하기 어렵다
▫️ 결국 '자동 추출'의 장점을 반감시키고, 스키마 설계 부담을 키움
▫️ 쿼리 시 neo4j schema를 그대로 LLM에 넘겨야 하는데, 10k+ 토큰이 될 수 있어 확장성에 한계가 있음
📍 Neo4j LLM Graph Builder
웹 인터페이스 기반 툴로, 문서를 업로드하면 LLM이 그래프를 구축하고 'chat with data'기능을 제공한다.
🔻 장점
▫️ 빠른 PoC, 소규모 데이터셋에서는 편리
▫️ Cypher 쿼리를 자동으로 생성
🔻 단점
▫️ 여전히 LLM 의존적
▫️ 대규모 데이터 확장성 부족
📍 OpenIE (Rule-based Open Information Extraction)
Standford CoreNLP, AllenNLP, SpaCy 기반
규칙 기반으로 (주어, 관계, 목적어) 추출하여 LLM을 거치지 않는다
🔻 장점
▫️ 빠른 PoC, 소규모 데이터셋에서는 편리
▫️ Cypher 쿼리를 자동으로 생성
🔻 단점
▫️ 여전히 LLM 의존적
▫️ 대규모 데이터 확장성 부족
📍 Microsoft GraphRAG
LLM 추출은 유지하면서도 '사후처리(post-processing)'로 그래프 품질을 개선하는 접근
🔻 핵심단계
1. LLM 기반 추출
2. 엔티티 그래프 구축 (가중치 부여)
3. Leiden 알고리즘 Community Detection
4. 각 커뮤니티를 요약해 '클러스터 보고서' 생성
🔻 질의방식
▫️ Global Search : 커뮤니티 요약문을 relevance 기준으로 점수화 후, Map-Reduce로 최종 답 생성
▫️ Local Search : 특정 엔티티의 주변 관계를 확장해 맥락 구성
🔻 장점
▫️ LLM 불일치 문제를 클러스터링으로 무력화
▫️ 반복 질의 시 커뮤니티 요약을 재사용해 비용 절감
🔻 단점
▫️ 초기 구축 비용이 크다 (LLM 호출 + 요약 생성)
📍 KGGen (Text-to-Knowledge-Graph)
KGGen은 오픈소스 툴킷으로, LLM을 활용해 텍스트를 지식 그래포 변환하는 파이프라인을 제공한다.
핵심은 트리플 추출 → 집계 → 클러스터링의 3단계 프로세스다
🔻 핵심단계
1. 추출 (Extract)
- 입력 테스트에서 (주어,관계, 목적어) 형태의 트리플을 LLM으로부터 추출
2. 집계 (Aggregate)
- 여러 문서에서 추출된 엔티티/관계를 모아 중복 제거 + 정규화
- 모든 엔티티/관계는 소문자로 변환 → embedding/검색에 유리
3. 클러스터링 (Cluster)
- 같은 의미를 가진 엔티티/관계를 LLM으로 그룹화
- LLM-as-a-Judge : 클러스터링 품질을 검증하는 단계 - LLM에게 두 엔티티가 동일한 개체인지 여부를 yes/no로 판단시킴
- 최종적으로, 덜 희소(sparse)하고 더 밀집(dense)한 그래프를 형성
왜 이렇게 하는가?
▫️ LLM 추출만 쓰면 그래프가 지나치게 산만하고 희소해져 reasoning이 어려움
▫️ KGGen은 중복 엔티티를 병합하고, 관계를 압축해 추론 친화적 그래프를 만든다
🔻 장점
▫️ 그래프 품질(밀집도, 추론 용이성) 향상
▫️ 소규모 데이터셋에서 효과적
🔻 단점
▫️ 여전히 LLM 호출이 많아 비용이 올라감 (추론 + 클러스터링 + 검증)
▫️ 질의/통합 문제 해결은 한계적 (검색/추론 단계는 직접 구현 필요)
📍 Zep AI Graphiti
Graphiti는 Zep AI에서 만든 오픈소스 프로덕션급 시계열(temporal) 지식 그래프 엔진이다.
단순히 그래프를 만드는 데서 끝나는 게 아니라, 시간 축, 증거 추적, 빠른 검색까지 지원한다.
🔻 핵심단계
1. 초기화 & 아키텍처
[3계층 모델 구조]
- LLM → ingestion(엔티티/관계 추출) 전용
- Embedder → 의미 검색 전용 (ex. OpenAI embeddings)
- Cross-Encoder → reranking 전용
2. Ingestion (삽입 단계)
- 문서 chunk → 'episode' 단위로 입력
- LLM이 엔티티/관계 추출
- 임베딩 생성
- neo4j 같은 그래프DB에 노드/엣지 저장
- 색인 구축 (BM25, 벡터 검색, 그래프 탐색, temporal index)
→ 삽입 시점에 모든 무거운 연산을 끝내므로, 이후 검색은 매우 빠르다
3. Hybrid 검색 구조
- BM25
- 벡터 검색
- 그래프 탐색
- reanker
4. Temporal Features (시간 인식 기능)
- 모든 fact에 valid_at, invalid_at, reference_time 속성이 붙음
- ex) 2019~2023 : 'MS는 OpenAI에 10억 달러 투자'
- 즉, 시점별로 무엇이 사실이었는지 추적 가능
- Agent Memory 모델링에 특히 유용
5. Provenance (출처 추적)
- 모든 관계/사실은 원본 episode(이메일, 대화, 문서 chunk)에 연결됨
- 나중에 '이 fact가 어디서 나온건지' 추적 가능
🔻 장점
▫️ LLM 호출을 ingestion 단계로만 제한해 실시간 검색 속도 개선
▫️ temporal reality : 사실의 유효 기간을 추적할 수 있어 '변화하는 지식' 처리 가능
▫️ provenance : 결과의 출처를 투명하게 확인 가능
🔻 단점
▫️ 초기 ingestion 비용(LLM 호출)이 큼
▫️ 파이프라인 설계, 운영 난이도 up