이번 장에서는 여러 예제를 통한 패턴 분석을 해볼 예정이다.
🚀 1. 월별 패턴 분석을 통한 계절성 발견
🔻 주요 학습 목표
▪️시계열 데이터에서 계절성의 개념을 이해하고, 월별 택시 수요 패턴을 통해 실제 계절성을 확인한다.
▪️pandas.resample() 함수를 활용해 시간 단위별(월별) 데이터 집계 방법을 익히고, 시계열 데이터의 주기적 패턴을 수치적으로 분석할 수 있다.
▪️ matplotlib을 사용한 막대그래프 시가고하 기법을 익히고, 월별 데이터의 변화 추이를 직관적으로 표현하여 계절성 패턴을 시각적으로 발견할 수 있다.
▪️시계열 데이터에서 최댓값, 최솟값, 변동폭을 계산하고 해석하여 계절성의 강도와 특성을 정량적으로 평가할 수 있다.
🔻 월별 집계와 막대그래프
🔸 resample()이란?
- 시계열 데이터를 특정 시간 단위로 그룹화하는 pandas 함수
- 시간별 -> 일별, 일별 -> 월별, 월별 -> 연별 등으로 데이터를 재구성할 수 있다.
- datetime 인덱스가 설정되어 있어야 사용 가능하다.
[매개변수]
- 'D' : Day 단위
- 'W' : Week 단위
- 'H' : Hour 단위
- 'Y' : Year 단위
🔸 집계 함수
- mean() : 평균
- sum() : 총합
- max() : 최댓값
- min() : 최솟값
- std() : 표준편차
- round(n) : 소수점 n자리까지 표시
# 월별로 리샘플링하여 'pickup_count' 컬럼의 평균을 계산합니다.
monthly_avg = df.resample('M')['pickup_count'].mean()
# 월 레이블을 수동으로 지정
months = ['1월', '2월', '3월', '4월', '5월', '6월', '7월', '8월', '9월', '10월', '11월', '12월']
# 플롯 크기 설정
plt.figure(figsize=(12, 6))
# 막대그래프 그리기
plt.bar(months, monthly_avg.values)
# 그래프 제목 설정
plt.title('2024년 월별 평균 택시 승차 건수', fontsize=16)
# X축, Y축 레이블 설정
plt.xlabel('월', fontsize=12)
plt.ylabel('평균 승차 건수', fontsize=12)
# 그래프 출력
plt.show()
🔻 패턴 찾아보기
🔸 idxmax() : 최댓값의 인덱스
🔸strftime('%B') : 날짜 형식 변환 - 전체 월 이름을 영어로 표시하는 예시
# monthly_avg의 최고값을 갖는 인덱스를 가져와서
# strftime('%B')로 해당 인덱스의 '월 이름(영문, 예: January)'을 문자열로 변환합니다.
max_month = monthly_avg.idxmax().strftime('%B') # 최고 달
# monthly_avg의 최저값을 갖는 인덱스의 월 이름(영문)을 가져옵니다.
min_month = monthly_avg.idxmin().strftime('%B') # 최저 달
# 최고값(수치)
max_value = monthly_avg.max()
# 최저값(수치)
min_value = monthly_avg.min()
# 최고값과 최저값의 차이(절대값)
difference = max_value - min_value
🚀 2. 시간대별 패턴 분석을 통한 일일 사이클 탐색
🔻 시간 정보 추출하기
# DatetimeIndex의 시(hour) 정보를 추출하여 'hour'라는 새 컬럼으로 추가합니다.
train_df['hour'] = train_df.index.hour
# 데이터프레임 상위 5개 행을 출력하여 'hour' 컬럼이 잘 들어갔는지 확인합니다.
train_df.head()
🔻 시간대별 평균 탑승 건수 계산
# 'hour'별로 그룹화(groupby)하여 'pickup_count'의 평균을 계산합니다.
hourly_avg = train_df.groupby('hour')['pickup_count'].mean()
# 결과 출력(소수점 1자리로 반올림해서 보기)
print(hourly_avg.round(1))
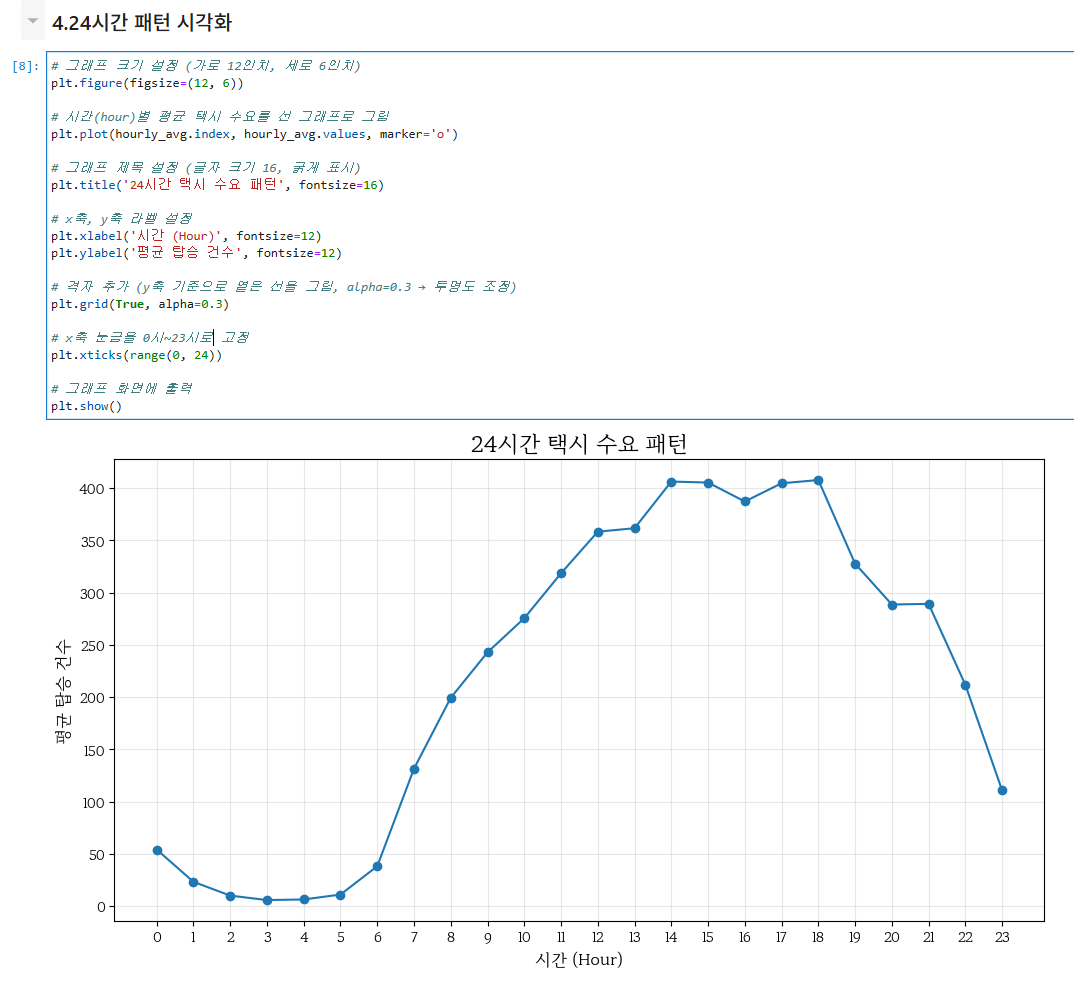
🔻 시간 패턴 시각화
# 그래프 크기 설정 (가로 12인치, 세로 6인치)
plt.figure(figsize=(12, 6))
# 시간(hour)별 평균 택시 수요를 선 그래프로 그림
plt.plot(hourly_avg.index, hourly_avg.values, marker='o')
# 그래프 제목 설정 (글자 크기 16, 굵게 표시)
plt.title('24시간 택시 수요 패턴', fontsize=16)
# x축, y축 라벨 설정
plt.xlabel('시간 (Hour)', fontsize=12)
plt.ylabel('평균 탑승 건수', fontsize=12)
# 격자 추가 (y축 기준으로 옅은 선을 그림, alpha=0.3 → 투명도 조정)
plt.grid(True, alpha=0.3)
# x축 눈금을 0시~23시로 고정
plt.xticks(range(0, 24))
# 그래프 화면에 출력
plt.show()
🚀 3. 요일별 패턴 분석을 통한 주간 사이클 이해
🔻 데이터 로딩 및 datetime 인덱스 설정
train_df = pd.read_csv('train.csv')
train_df['datetime'] = pd.to_datetime(train_df['datetime'])
train_df.set_index('datetime', inplace=True)
train_df
🔸 inplace = True 매개변수
- False (기본값) : 새로운 데이터프레임을 반환
- True (메모리 효율적) : 기존 데이터프레임을 바로 변경
🔻 요일 번호 추출하기
# 인덱스(날짜)에서 요일 번호(0=월요일, 6=일요일)를 추출해 새로운 컬럼 'weekday'로 저장합니다.
train_df['weekday'] = train_df.index.weekday
🔸 weekday 속성이란?
- datetime 인덱스에서 요일을 숫자로 변환해주는 속성이다.
- ISO 8601 표준을 따라서 월요일이 0, 일요일이 6으로 설정된다.
- 스테이지3에서 배운 .hour 속성과 동일한 방식으로 작동한다.
요일 번호 체계
- 0 : Monday (월요일)
- 1 : Tuesday (화요일)
....
- 6 : Sunday (일요일)
왜 숫자로 변환하는가?
- 그룹화 정렬이 쉬워진다
- 수치 계산이 가능해진다 (평균, 통계 등)
- 조건부 필터링에 유용하다 (예. 주중 vs 주말)
🔻 요일 이름 추출하기
# 인덱스(날짜)에서 요일 이름('Monday', 'Tuesday', ...)을 추출해 'weekday_name' 컬럼으로 저장합니다.
train_df['weekday_name'] = train_df.index.day_name()
🔸 day_name() 함수란?
요일을 영어 이름으로 반환하는 함수다.
숫자보다는 직관적인 이해가 가능해지고, 시각화나 보고서에서 더 읽기 쉬워진다는 장점이 있다.
반환 형식
- 전체 요일 이름 : Monday, Tuesday, Wednesday,...
- 영어 기준 : 한국어 환경에서도 영어로 반환된다.
다중 컬럼 선택하여 결과 확인하기 : [['컬럼1', '컬럼2', '컬럼3']].head(10)
- 대괄호 안에 리스트 형태로 여러 컬럼을 선택할 수 있다.
# pickup_count, weekday(요일 번호), weekday_name(요일 이름) 컬럼의 상위 10행을 출력해 결과를 확인합니다.
train_df[['pickup_count', 'weekday', 'weekday_name']].head(10)
🔻 요일별 데이터 개수 확인
# 'weekday_name' 컬럼에서 요일별 등장 횟수를 집계합니다.
# 반환값은 요일(인덱스)과 개수(값)로 이루어진 pandas Series이며,
# 기본적으로 개수가 많은 순서로 정렬되어 있습니다.
weekday_counts = train_df['weekday_name'].value_counts()
# 실제 집계 결과(Series)를 출력합니다.
print(weekday_counts)
🔸 value_counts() : 값별 개수 집계
- 각 고유값이 몇 번 등장하는지 세어주는 함수
- 카테고리별 데이터 분석에서 가장 먼저 사용되는 탐색 도구다
- 자동으로 개수가 많은 순서대로 정렬해서 결과를 보여준다
반환 형식
- pandas Series 객체를 반환
- 인덱스: 고유값들 (Monday, Tuesday, ...)
- 값: 각 고유값의 등장 횟수 (1248, ...)
🔻 요일별 평균 탑승 건수 계산
# 요일 이름(예: 'Monday', 'Tuesday'...)을 기준으로 그룹화하여
# 각 요일별 'pickup_count' 평균값을 계산합니다.
weekday_avg = train_df.groupby('weekday_name')['pickup_count'].mean()
weekday_avg
🔸 groupby()
- 특정 컬럼을 기준으로 데이터를 그룹화
🔸 mean()
- 그룹화된 각 요일에 대해 평균값을 계산 -> 각 요일의 대표적인 수요 수준을 확인할 수 있음
반환 형식
- pandas Series 객체
- 인덱스 : 요일 이름(Monday, Tuesday, ...)
- 값 : 각 요일의 평균 pickup_count
🔻 요일 순서 정렬하기
# 요일 순서를 월~일로 고정하기 위해 순서 리스트를 정의합니다.
weekday_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekday_order
미리 정의해두기
🔻 인덱스 재정렬하기
# 앞서 정의한 요일 순서를 기준으로 weekday_avg Series의 인덱스를 재정렬합니다.
# reindex()를 사용하면 기존 데이터 순서를 바꾸지 않고 정해진 순서대로 재배치할 수 있습니다.
weekday_avg = weekday_avg.reindex(weekday_order)
weekday_avg
🔸 .reindex(변수)
- 변수를 기준으로 인덱스를 재정렬
🔻 요일별 수요 시각화
# 1) 그래프 크기 설정: 가로 8, 세로 4 인치
plt.figure(figsize=(8, 4))
# 2) 막대 색상 지정
# 주말('Saturday', 'Sunday')은 'skyblue', 평일은 'lightcoral' 색상으로 구분합니다.
colors = ['skyblue' if day in ['Saturday', 'Sunday'] else 'lightcoral' for day in weekday_avg.index]
# 3) 막대그래프(bar chart) 그리기
# x축: 0~6 (요일 순서), y축: weekday_avg 값
# alpha=0.8은 막대 투명도 설정으로, 배경 격자선이 적절히 보이게 함
plt.bar(range(len(weekday_avg)), weekday_avg.values, color=colors, alpha=0.8)
# 4) 그래프 제목 설정
plt.title('요일별 평균 택시 수요', fontsize=12, fontweight='bold')
# 5) x축, y축 라벨 설정
plt.xlabel('요일', fontsize=12)
plt.ylabel('평균 탑승 건수', fontsize=12)
# 6) x축 눈금에 실제 요일 이름(한글)을 표시
# weekday_avg의 인덱스 순서(월~일)에 맞게 ['월','화','수','목','금','토','일']로 표시
plt.xticks(range(len(weekday_avg)), ['월', '화', '수', '목', '금', '토', '일'])
# 7) 격자선 표시 (y축만)
# alpha=0.3으로 투명도를 조절해 데이터 시각화를 방해하지 않도록 설정
plt.grid(True, alpha=0.3, axis='y')
# 8) 그래프 출력
plt.show()
작동원리
- weekday_avg.index의 각 요일(day)을 순서대로 확인
🔸 plt.xticks() - X축 라벨 한글화
ragne(len(weekday_avg)) : 0~6 위치에
['월','화',....'일'] : 한글 요일명 표시
🔸 plt.grid(True, alpha=0.3, axis='y') - Y축 전용 격자
axis='y' -> Y축에만 격자선 표시
🔻 Insight
1. 완벽한 '역U자형' 패턴 : 그래프가 월요일에서 시작해서 목요일에서 정점을 찍고 일요일로 하락하는 곡선
2. 주중 vs 주말의 극명한 대비 : 색상 구분으로 평일과 주말의 차이가 한 눈에 보임 + 사회적 활동 리듬이 택시 수요에 그대로 반영됨
3. 금요일의 특별한 위치 : 평일이지만 주말을 향한 하락이 시작되는 전환점 + '불금'이라는 말과 달리 택시 수요는 목요일보다 낮음
🚀 4. 평일 vs 주말 비교 분석
월별 패턴에서는 12월이 최고, 8월이 최저라는 75.2% 계절 차이를 발견했다.
시간대별 패턴에서는 오후 6시가 최고, 새벽 3시가 최저라는 무려 68배 차이를 확인했다.
요일별 패턴에서는 목요일이 최고, 일요일이 최저라는 88.8%차이를 발견했고, 특히 주중과 주말의 뚜렷한 색상 대비를 통해 패턴을 시각적으로 확인했다.
하지만 각 요일의 개별적 특성만 봤을 뿐, 평일과 주말이라는 큰 그룹으로 나누어 비교하지는 않았다.
평일과 주말의 시간대별 패턴 차이, 출근시간 러시가 주말에도 나타나는지, 주말 밤이 평일 밤보다 더 바쁜지에 대한 분석이 필요하다. 따라서 이번에는 '평일 vs 주말'이라는 이분법적 관점으로 택시 수요 패턴을 분석하고, 두 그룹 간의 차이점과 공통점을 명확하게 비교해보도록 하자.
🔻 데이터 로드 및 요일 정보 추출
import pandas as pd
import numpy as np
import matplotlib.pyplot as plttrain_df = pd.read_csv('train.csv')
train_df['datetime'] = pd.to_datetime(df['datetime'])
train_df.set_index('datetime', inplace=True)
train_dftrain_df['weekday'] = train_df.index.weekday
trian_df['weekday_name'] = train_df.index.day_name()
train_df[['pickup_count', 'weekday', 'weekday_name']].head(10)
📌 평일과 주말 구분
🔻 주말 여부 판별 컬럼 생성
train_df['is_weekend'] = train_df['weekday'].isin([5,6])
🔸 isin()
- 특정 값들이 리스트에 포함되어 있는지 확인하는 함수
🔻 평일/주말 데이터 분할
weekday_data = train_df[~train_df['is_weekend']]
🔸 ~ 연산자
- Boolean 값을 반대로 뒤집는 연산자
weekend_data = train_df[train_df['is_weekend']]
🔸 Boolean 인덱싱
- True인 행만 선택하는 pandas의 핵심 기능
- train_df[조건] -> 조건이 True인 행들만 추출
🔻 데이터 분할 결과 확인
print(f"평일 데이터: {len(weekday_data):,}개")
🔸 len() 함수와: , 포맷팅
- :, -> 천 단위 콤파 표시 (6168 -> 6,168)
📌 평일과 주말 평균 비교
🔻 각 그룹의 평균 계산
weekday_avg_total = weekday_data['pickup_count'].mean()
🔻 비율 분석
print(f"주말/평일 비율: {weekend_avg_total/weekday_avg_total:.2f} ({(weekend_avg_total/weekday_avg_total)*100:.1f}%)")
📌 시간대별 평일, 주말 패턴 비교
🔸 .index.hour : datetime 인덱스에서 0~23 사이의 시간 값을 반환
weekday_data['hour'] = weekday_data.index.hour
weekend_data['hour'] = weekend_data.index.hour
# 평일/주말 데이터에서 시간(hour) 단위로 그룹화하여 각 시간대별 pickup_count 평균값을 계산합니다.
weekday_hourly = weekday_data.groupby('hour')['pickup_count'].mean()
weekend_hourly = weekend_data.groupby('hour')['pickup_count'].mean()
print(f"평일 시간대별 평균(건):\n{weekday_hourly.round(1)}")
print(f"주말 시간대별 평균(건):\n{weekend_hourly.round(1)}")
📌 평일, 주말 시간별 패턴 시각화
# 그래프 크기 설정: 가로 14, 세로 6 인치
plt.figure(figsize=(14, 6))
# 평일 라인: 파란 실선('b-'), 원형 마커('o'), 선 굵기 2, 마커 크기 6
# x축은 시간(hour: 0~23), y축은 시간대별 평균 승차 건수
plt.plot(
weekday_hourly.index, weekday_hourly.values, 'b-', marker='o',
linewidth=2, markersize=6, label='평일'
)
# 주말 라인: 빨간 실선('r-'), 사각형 마커('s'), 선 굵기 2, 마커 크기 6
plt.plot(
weekend_hourly.index, weekend_hourly.values, 'r-', marker='s',
linewidth=2, markersize=6, label='주말'
)
# 제목 설정(굵게)
plt.title('평일 vs 주말 시간대별 수요 패턴', fontsize=16)
# 축 라벨 설정
plt.xlabel('시간 (Hour)', fontsize=12)
plt.ylabel('평균 탑승 건수', fontsize=12)
# 범례 표시
plt.legend(fontsize=15)
# 보조 격자 표시(투명도 30%)
plt.grid(True, alpha=0.3)
# X축 눈금: 0~23까지 모두 표시해 시간대 비교를 쉽게 함
plt.xticks(range(0, 24))
# 그래프 출력
plt.show()

'대회 및 공모전' 카테고리의 다른 글
| [Dacon] [시계열 기초] 1. 시계열 데이터 및 프로젝트 개요 (0) | 2026.02.22 |
|---|---|
| [Bookflow] Neon DB를 통한 클라우드 DB 설치하기 (0) | 2025.11.11 |
| [BookFlow] 출판물 폐기 도서 & 폐지 활용 서비스 개요 (0) | 2025.11.11 |
| [DACON 학습] 2. AI 에이전트와 LangGraph의 기초 (0) | 2025.10.17 |
| [DACON 학습] 1. AI 에이전트의 첫걸음 (0) | 2025.10.17 |