📌 ICIJ Data : 정치인, 범죄자, 그리고 그들의 자금을 숨기는 불법 산업을 연결하는 데이터
아래는 Neo4j Sandbox에 적혀있는 해당 데이터에 관한 설명이다 :
Neo4j에서 작업 중인 ICIJ 오프쇼어 유출(Offshore Leaks) 데이터베이스는 Pandora Papers, Paradise Papers, Panama Papers 및 기타 오프쇼어 유출 조사에 포함된 80만 개 이상의 역외 법인 정보를 담고 있는 자료이다. 이 데이터는 오랜 기간에 걸친 활동을 다루고 있으며, 200개 이상의 국가와 지역에 있는 개인 및 기업들과의 연관성을 보여준다.
이 데이터베이스의 진정한 가치는 조세피난처에 설립된 회사 및 신탁을 둘러싼 비밀을 걷어내고, 그 뒤에 숨겨진 실제 인물을 드러낸다는 점에 있다. 여기에 가능한 경우, 해당 불투명한 구조의 실제 소유자 이름도 포함된다. 총 50만 개 이상의 개인 및 기업의 이름이 비밀스러운 역외 구조 뒤에 있는 실체로 드러나 있다. 이 정보는 표준화된 법인 등록정보가 아닌 유출된 기록에서 비롯된 것이므로, 중복이 존재할 수 있다. 따라서 데이터베이스에서 특정 인물이나 법인을 식별할 경우에는 주소나 기타 식별 가능한 정보를 바탕으로 신원을 검증하는 것이 바람직하다.
역외 법인이나 신탁을 합법적으로 사용하는 경우도 분명히 존재한다. 이 데이터베이스는 여기에 포함된 어떤 개인, 회사, 기타 법인이 불법 행위를 저질렀거나 부적절하게 행동했다는 점을 암시하거나 주장하려는 의도를 갖고 있지 않다. 만약 데이터베이스에서 오류를 발견한 경우에는 ICIJ에 연락하는 것이 좋다.
🔻 The Shape Of the Data
Offshore Leaks 데이터베이스는 데이터 내의 연결 관계를 활용할 수 있도록 언론인과 연구자들이 사용하기 위해 Neo4j에 임포트된 것이라고 한다.
CALL db.schema.visualization;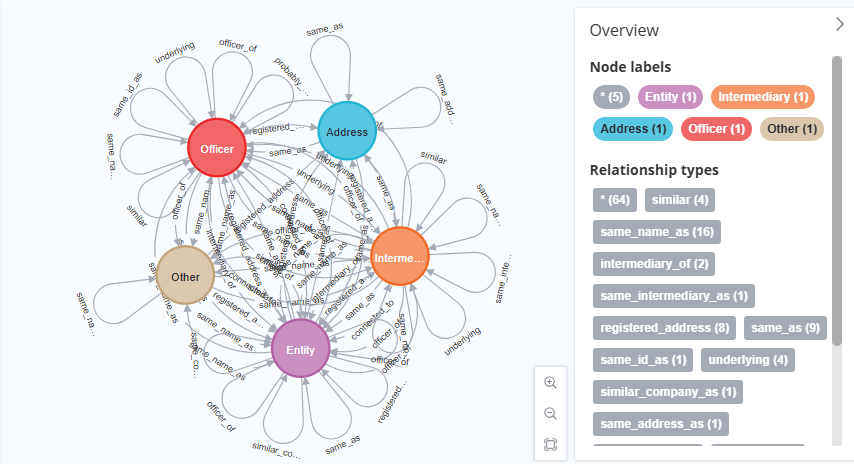
📍 노드 유형
▪️ Entity (개체) : 역외 법인으로, 조세 부담이 낮은 관할 구역에서 설립된 회사, 시탁, 재단 또는 기타 법적 실체
▪️ Officer (임원) : 역외 법인에서 수익자, 이사, 주주 등으로 역할을 수행하는 개인 또는 회사.
▫️ 다이어그램에 나타난 관계는 존재하는 여러 관계 중 일부 사례에 불과함
▪️ Intermediary (중개인) : 역외 회사를 원하는 사람과 역외 서비스 제공자 사이를 중개하는 인물. 보통 로펌이나 중간 업체로, 역외 서비스를 제공하는 회사에 회사를 설립해 달라고 요청하는 역할을 함
▪️ Address (주소) : ICIJ가 확보한 원본 데이터베이스에 나타난 등록 주소
▪️ Other : 데이터에서 발견된 기타 실체들
📍 관계 유형
#모든 관계 타입 찾기
MATCH (n)-[r]->(m)
WITH labels(n) AS fromLabel, type(r) AS relType,
collect(distinct head(labels(m))) AS toLabels,
count(*) AS frequency
WHERE frequency > 1000
RETURN fromLabel, relType, toLabels, frequency ORDER BY frequency DESC;
▪️ similar : 유사한 속성이나 역할을 가진 노드들 사이의 관계
▫️ex. 이름, 주소 또는 활동 유형이 비슷한 두 개체
▪️ same_name_as : 동일한 이름을 가진 노드들 간의 연결
▫️ex. 다른 국가에 존재하지만 이름이 같은 두 법인이나 개인
▪️ intermediary_of : 특정 개체의 중개인임을 나타냄
▫️ex. 로펌이나 에이전트가 법인을 대신하여 설립하거나 운영할 경우
▪️ same_intermediary_as : 같은 중개인을 공유하는 두 개체 간의 관계
▫️ex. 서로 다른 두 법인이 동일한 로펌에 의해 설립됨
▪️ registered_address : 개체가 특정 주소에 등록되어 있다는 관계
▫️ex. 회사가 조세피난처의 특정 주소에 등록되어 있음
▪️ same_as : 동일한 실체일 가능성이 높음을 나타냄
▫️ex. 데이터 중복이나 유사한 속성으로 인해 동일 인물로 추정
▪️ same_id_as : 같은 고유 ID를 갖는 노드들 간의 연결
▫️ex. 시스템상 중복되었으나 동일한 ID로 식별되는 경우
▪️ underlying : 어떤 개체가 다른 개체의 실질적 소유자임을 나타냄
▫️ex. 개인 A가 법인 B의 실제 소유주인 경우
▪️ similar_company_as : 비슷한 특성을 가진 회사들 간의 관계
▫️ex. 설립 국가, 중개인, 주소 등에서 유사성을 공유하는 법인
▪️ same_address_as : 동일한 주소를 사용하는 개체들 간의 연결
▫️ex. 수십 개의 역외 법인이 동일 주소에 등록되어있음
▪️ connected_to : 일반적인 연관성을 나타냄. 다양한 유형의 연결을 포괄
▫️ex. 사업 파트너, 수익자, 법적 관계 등
▪️ officer_of : 특정 개인이나 회사가 법인의 임원 또는 관련자임을 나타냄
▫️ex. A씨나 B법인의 이사로 등록됨
▪️ probably_smae_officer_as : 동일 인물일 가능성이 높은 임원들 간의 관계
▫️ex. 철자 차이나 데이터 오류로 인해 다르게 보이지만 동일인 가능성
▪️ same_company_as : 동일 법인일 가능성이 높은 노드 간 연결
▫️ex. 여러 번 중복 등록된 회사 데이터 간 연결
Offshore Leaks 데이터는 사람들과 역외 법인 간의 일련의 연결 관계를 드러낸다.
이러한 사람들과 법인 사이의 관계를 탐색하는 데에는 그래프 데이터베이스가 가장 적합한 방식이다.
SQL 데이터베이스나 다른 유형의 NoSQL 데이터베이스보다 훨씬 직관적으로 사용할 수 있기 때문이다.
예를 들어, 두 명의 법인 임원(Officer) 사이에 Entity나 Address 노드를 경유하는 최단 경로를 찾고 싶다고 가정해보자.
MATCH (a:Officer), (b:Officer)
WHERE a.name CONTAINS 'Ross, Jr' AND b.name CONTAINS 'Grant'
MATCH p=allShortestPaths((a)-[:officer_of|intermediary_of|registered_address*..10]-(b))
RETURN p
LIMIT 50
위 구문에서와 같이 여러 관계 타입 목록을 나열할 때는 [:...|...|...] 식으로 작성한다.
경로 길이를 지정할 때는 *..n 식으로 작성하면 되며, 최소 1개 이상 최대 n개 이하로 이어진 경로를 의미한다.
참고로, *0..10이라고 하면 길이 0 (즉, 자기 자신과의 관계)도 허용하게 된다.
따라서 위 구문은 officer_of, intermediary_of, registered_address 세 가지 관계 중 하나 이상으로 연결된 노드를, 1~10 단계 이내에서 탐색하라는 의미가 된다.
📌 Graph Patterns
Neo4j의 질의 언어인 Cypher는 그래프 패턴을 중심으로 구성되어 있다.
그래프 패턴은 괄호를 사용해 엔터티를 나타내며, 예를 들어 (e:Entity)와 같이 표현한다.
또한 화살표를 통해 관계를 표현하는데, 예를 들어 -[:intermediary_of]->와 같이 사용된다.
:Entity와 :intermediary_of는 각각 엔터티 유형과 관계 유형을 나타낸다.
예를 들어 (:Intermediary)-[:intermediary_of]->(:Entity) 라는 패턴을 만들 수 있고, MATCH 절을 사용해 찾을 수 있다.
| filter | WHERE intermidary.name CONTAINS 'MOSSACK' |
| aggregate | WITH e.jurisdiction AS country, COUNT(*) AS frequency |
| return | RETURN country, frequency |
| order | ORDER BY frequency DESC |
| limit | LIMIT 20; |
🔹 Relationships
위에서 전체 관계를 파악하기 위한 구문을 통해 관계를 파악하면 되는데, 사용된 함수에 대해 더 살펴보자.
▪️labels(n) : 노드 n이 갖는 모든 라벨 목록을 리스트 형태로 반환한다.
▫️ex. [:Officer, Person] → ["Officer", "Person"]
▪️type(r) : 관계 r의 타입(relationship type)을 문자열로 반환한다.
▫️ [:officer_of] → "officer_of"
▪️collect(...) : WITH 또는 RETURN 절에서 여러 값을 하나의 리스트로 모을 때 사용한다.
▪️head(...) : 리스트의 첫 번째 요소를 반환한다.
▫️head(["Entity", "Company"]) → "Entity"
이제 각각의 노드들이 갖는 속성들을 파악해보자.

🔻 Intermediary
각 Intermediary 노드는 역외 법인을 원하는 사람과, 역외 서비스 제공자 사이의 중개인을 나타낸다.
중개인은 일반적으로 로펌이나 중간 브로커로, 역외 서비스 제공자에게 중개인을 위한 역외 회사를 설립해달라고 요청하는 역할을 한다.
속성
- name : 중개인의 이름
- address : 중개인의 주소
- sourceID : 데이터 출처에 따라 Offshore Leaks, Panama Papers, 또는 Paradise Papers 중 하나
- status : 상태 정보
- valid_until : 유효기간
🔻 Entity
각 Entity 노드는 저세율의 역외 관할 구역에서 에이전트에 의해 설립된 회사, 신탁 또는 펀드를 나타낸다.
속성
- name: 법인의 이름
- sourceID: 데이터 출처에 따라 Offshore Leaks, Pandora Papers, Panama Papers, 또는 Paradise Papers 중 하나
- address : 이 필드는 해당 Entity와 연결된 등록 주소가 중개인과 동일한 경우에만 주소 정보를 포함한다. 그렇지 않은 경우, 등록 주소 정보는 registered_address 관계를 통해 이 Entity 노드와 연결된 별도의 주소(Address) 노드에 저장된다.
- former_name, original_name : 이전 이름 또는 원래 이름을 나타낸다.
🔻 Officer
각 Officer 노드는 역외 법인의 수익자, 이사, 주주 등을 타나내는 노드다..
수익자(beneficiary), 주주(shareholder), 이사(director) 등과 같은 역할을 수행하는 개인 또는 기업
속성
- name : Officer의 이름
- valid_until : 유효 기간
- sourceID : 데이터 출처에 따라 Offshore Leaks, Pandora Papers, Panama Papers, 또는 Paradise Papers 중 하나
- country_code, countries : 관련된 국가 코드 또는 국가 이름
🔻 Address
Inermediary, Officer 또는 Entity에 대해 기록된 주소를 나타내는 노드
속성
- address : 기록에 나타난 주소
- sourceID : 데이터 출처에 따라 Offshore Leaks, Pandora Papers, Panama Papers, 또는 Paradise Papers 중 하나
- valid_until : 주소의 유효 기간
- country_codes, countries : 주소와 관렬ㄴ된 국가 코드 및 국가 이름
✏️ Pandora Papers
🔹 Overview
전체 노드와 관계를 보기 위해서 CALL db.schema.visualization()을 사용하면 된다는 것은 이제 익숙해져있을 것이다.
소스 데이터에서 entity type당 개수를 보고 싶다면,
MATCH (node)
WHERE node.sourceID STARTS WITH "Pandora Papers"
RETURN labels(node) AS type, count(*)
🔹 Visual vs Tabular Results
> 시각적 결과를 위한 쿼리
그래프를 Cypher로 질의할 때는 그래프 패턴 매칭을 기반으로 한다.
예를 들어, "Intermediary가 Entity 노드와 intermediary_of 관계로 연결되어 있는 패턴은 다음과 같이 정의할 수 있다
(i:Intermediary)-[r:intermediary_of]->(e:Entity)
여기서 i, e, r은 각각 나중에 WHERE 절이나 RETURN 절에서 필터링 또는 결과 반환 시 사용하는 변수이며,
하나의 Cypher 문장 내에서 재사용 가능한 별칭(alias)이다.
Intermediary에 의해 등록된 Entity를 찾고 싶다면,
MATCH (i:Intermediary)-[r:intermediary_of]->(e:Entity)
WHERE i.name CONTAINS "SFM CORPORATE SERVICES S.A." AND e.sourceID STARTS WITH "Pandora Papers"
RETURN i, r, e LIMIT 100
이 쿼리의 결과는 그래프 형태로 시각화된다!
> 표 형식 결과를 위한 쿼리
이번에는 “Officer 노드가 officer_of 관계를 통해 Entity 노드와 연결되어 있는 패턴”에 대해 질의한다고 가정한다면
(o:Officer)-[:officer_of]→(e:Entity)
이후 각 Officer가 연결된 Entity 개수를 집계하고, 그 수를 기준으로 정렬한다면
MATCH (o:Officer)-[:officer_of]→(e:Entity)
WHERE o.sourceID STARTS WITH "Pandora Papers"
RETURN o.name, count(*) AS entities
ORDER BY entities DESC
LIMIT 10
🔹 Investigating individual people and entities
> 이름으로 Officer 노드 찾기
재사용이 가능하도록 파라미터 변수에 officer의 이름을 저장할 수 있다.
:param offcier => "ORLOV"
그리고 이 변수를 사용하려면 $officer 로 사용이 가능하다
MATCH (o:Officer)
WHERE o.name CONTAINS $officer AND o.sourceID STARTS WITH "Pandora Papers"
RETURN o
LIMIT 100
> 임원 검색하고 연결 관계 찾기
임원이 어떤 엔티티들과 관련되어 있었는지, 1차 및 2차 연결 관계를 통해 확인하기
- 1차 연결 (1st degree)
MATCH (o:Officer)
WHERE o.name CONTAINS $officer AND o.sourceID STARTS WITH "Pandora Papers"
MATCH path = (o)-[r]->(:Entity)
RETURN path
LIMIT 100
- 2차 연결 (2nd degree)
MATCH (o:Officer)
WHERE o.name CONTAINS $officer AND o.sourceID STARTS WITH "Pandora Papers"
MATCH path = (o)-[]->(:Entity)<-[]-(:Officer)-[]->(:Entity)
RETURN path
LIMIT 100
이 임원이 직접 연결된 Entity를 찾고, 이 entity와 연결된 다른 officer를 찾은 다음 이 다른 officer가 연결되어있는 다른 Entity를 찾는 구문
> 어떤 엔티티 뒤에 누가 있고, 그들이 어떤 역할을 하는지 알아보기
엔티티 이름이 DANSUNN FINANCE LTD.라고 가정하면,
- 파라미터 설정
:param entity => "DANSUNN FINANCE LTD."
- 관련된 임원 및 역할 찾기
MATCH (e:Entity)-[r]-(o:Officer)
WHERE e.name CONTAINS $entity AND e.sourceID STARTS WITH "Pandora Papers"
RETURN *
LIMIT 100
✏️ Paradise Papers
🔹 Joint involvement
> 기본 공동 관여 쿼리
조사 시, 함께 활동하는 것으로 보이는 인물들을 식별하는 것이 매우 중요하다.
이 쿼리를 통해 두 명의 임원이 같은 entity에 반복적으로 연결되어 있는지를 찾아볼 수 있다.
참고로 일부 결과는 회사명이 나올 수 있는데, 이는 회사 또한 엔티티의 임원이 될 수 있기 때문이다.
MATCH (o1:Officer)-[r1]->(e:Entity)<-[r2]-(o2:Officer)
USING JOIN ON e
WHERE id(o1) < id(o2)
AND size((o1)--()) > 10
AND size((o2)--()) > 10
AND o1.sourceID STARTS WITH "Paradise Papers"
WITH o1, o2, count(*) AS freq, collect(e)[0..10] AS entities
WHERE freq > 10
WITH * ORDER BY freq DESC LIMIT 10
RETURN o1.name, o2.name, freq, [e IN entities | e.name]
▪️JOIN ON
USING JOIN ON 이 나오길래 sql의 join과 비슷한 것인지해서 찾아보니 아니었다.
지금 위 구문의 MATCH에서는 Entity인 e를 중심으로 같은 엔티티에 공동으로 연결된 두 사람을 찾고 싶은 상황이다.
만약 JOIN을 사용하지 않으면 잘못된 조인 순서를 선택해서 비효율적으로 쿼리 계획을 세울 수 있다.
먼저 Officer를 전부 순회하고 그 다음 Entity를 거쳐서 상대방 Officer를 찾는 구조로 짜면
노드 수가 매우 많을 경우 조합 수가 폭발적으로 커지고 성능이 급락할 수 있다.
USING JOIN ON e를 하면 e를 기준으로 먼저 고르고, e에 연결된 Officer들을 가져와서 조합쌍을 생성하므로 효율적이다!
▪️ (o1)--()
노드 사이의 '--'은 어떤 노드와 어떤 방향이든 관계가 하나라도 있는지를 의미하는 패턴 매칭이다.
-- 은 방향 없는 관계로, ->, <-, <--> 을 모두 포함한다.
따라서 위 구문은 o1이 연결된 모든 관계를 파악하고자 하는 것이다.
▪️ [e IN entities | e.name]
위에서도 [ | ] 에 대해서 이야기한 바가 있다.
이에 대해 더 자세하게 살펴보자~ 이건 cypher의 리스트 내장 문법이고 구조는 다음과 같다
[<변수> IN <리스트> | <표현식>]
따라서 entities 리스트 안의 각 노드 e에 대해, e.name만 추출해서 새로운 리스트를 만들라는 말이 되어 결과는 :
[e1.name, e2.name, e3.name, ..., e10.name] 식이 된다.
근데 문득 그냥 entities.name을 리턴하면 되는거 아닌가?하는 의문이 들었다.
하지만 cypher에서는 리스트 전체의 필드를 한 번에 호출하는 문법을 지원하지 않는다.
entities는 아래와 같은 노드 객체들의 리스트다.
entities = [
(:Entity {name: "ABC Corp"}),
(:Entity {name: "XYZ Ltd"}),
(:Entity {name: "Omega Holdings"})
]
cypher은 entities 안의 각 노드가 개별 객체라는 사실을 전제로 하기 때문에, entities.name처럼 리스트 전체에 대한 속성 접근은 허용하지 않는다.
따라서 RETURN entities.name이라고 하면 오류가 발생할 것이다.
파이썬에서 [e.name for e in entities]와 같은 형태로 사용하는 것과 유사하게 생각하면 편한듯!
> 기업 이름이 포함된 임원을 필터링에서 제외
결과에서 회사들을 걸러내기 위해, 임원 이름에 "LLC", "Limited", "Ltd" 등과 같이 회사명에 흔히 포함되는 문자열이 들어간 경우를 제외할 수 있다.
MATCH (o1:Officer)-[r1]->(e:Entity)<-[r2]-(o2:Officer)
USING JOIN ON e
WHERE id(o1) < id(o2)
AND NOT o1.name CONTAINS "LIMITED"
AND NOT o1.name CONTAINS "Limited"
AND o1.sourceID STARTS WITH "Paradise Papers"
AND NOT o2.name CONTAINS "LIMITED"
AND NOT o2.name CONTAINS "Limited"
AND size((o1)--()) > 10
AND size((o2)--()) > 10
WITH o1, o2, count(*) AS freq, collect(e)[0..10] AS entities
WHERE freq > 10
WITH * ORDER BY freq DESC LIMIT 10
RETURN o1.name, o2.name, freq, [e IN entities | e.name]
> 가상 관계를 이용한 그래프 시각화
이 그래프를 가상 관계를 활용해 시각화 해보자.
MATCH (o1:Officer)-[r1]->(e:Entity)<-[r2]-(o2:Officer)
USING JOIN ON e
WHERE id(o1) < id(o2)
AND NOT o1.name CONTAINS "LIMITED"
AND NOT o1.name CONTAINS "Limited"
AND o1.sourceID STARTS WITH "Paradise Papers"
AND NOT o2.name CONTAINS "LIMITED"
AND NOT o2.name CONTAINS "Limited"
AND size((o1)--()) > 10
AND size((o2)--()) > 10
WITH o1, o2, count(*) AS freq, collect(e)[0..10] AS entities
WHERE freq > 200
RETURN o1, o2, apoc.create.vRelationship(o1, 'JOINT', {freq: freq, entities: [e IN entities | e.name]}, o2)
APOC의 vRelationship을 사용해 가상의 관계(JOINT)를 생성하여 그래프 시각화용 데이터로 출력하는 예제다.JOINT 관계 안에 연결된 entity들의 이름도 함께 속성으로 포함하고 있다.
🔹 Shortest path between two people
여기서 사람이 Smith와 Grant라고 했을 때,
MATCH (a:Offcier), (b:Offcier)
WHERE a.name CONTAINS 'Smith' AND b.name CONTAINS 'Grant' AND a.sourceID STARTS WITH 'Paradise Papers'
WITH a,b LIMIT 20000
MATCH a=allShortestPaths((a)-[:officer_of|intermediary_of|registered_address*..10]-(b))
RETURN p
LIMIT 50
🔹 Query by address
MATCH (a:Address)<-[:registered_address]-(other)
WHERE a.address CONTAINS 'Barcelona' AND a.countries CONTAINS 'Spain' AND a.sourceID STARTS WITH "Paradise Papers"
RETURN a, other
LIMIT 100
🔹 Offshore entity jurisdictions by intermediary
중개인에 따른 역외 법인 관할지를 찾고자 한다면, 특정 중개인이 관리하는 역외 법인(offshore entity)들은 어떤 관할지(jurisdiction)에 등록되어 있는지를 조회해야한다.
MATCH (i:Intermediary)-[:intermediary_of]->(e:Entity)
WHERE i.name CONTIANS 'Appleby' AND i.sourceID STARTS WITH "Paradise Papers"
RETURN e.jurisdiction_description AS jurisdiction, count(*) AS number
ORDER BY number
LIMIT 10
🔹 Most popular offshore jurisdiction for people connected to a country
특정 국가에 주소지를 둔 임원들(officer)이 이용한 대표적인 역외 법인 등록 관할지는 무엇인가?
MATCH (o:Officer)->(e:Entity)<-[:intermediary_of]-(i:intermediary)
WHERE e.country_codes CONTAINS 'USA' AND o.sourceID STARTS WITH "Paradise Papers"
RETURN e.jurisdiction_description AS jurisdiction, count(*) AS number
ORDER BY number LIMIT 10
🔹 Offshore entity jurisdictions by intermediary
특정 도시에 주소지를 둔 사람들이 자주 사용하는 역회 법인의 관할지(jurisdiction)은 어딘가?
MATCH (a:Address)<-[:registered_address]-(o:Officer), (o)->(e:Entity)<-[:intermediary_of]-(i:Intermediary)
WHERE a.address CONTAINS 'London' AND a.countries CONTAINS 'United Kingdom'
RETURN e.jurisdiction_description AS jurisdiction, count(*) AS number
ORDER BY number DESC LIMIT 10
🔹Most popular intermediaries for people with an address in a certain city
특정 도시 주소를 가진 사람들과 가장 많이 연관된 중개인
MATCH (o:Officer)-[:registered_address]->(a:Address), (o)-->(e:Entity)<-[:intermediary_of]-(i:Intermediary)
WHERE a.address CONTAINS 'Isle of Man' AND a.sourceID STARTS WITH "Paradise Papers"
RETURN i.name AS intermediary, count(DISTINCT e) AS number
ORDER BY number DESC LIMIT 10
🔹 전체 텍스트 검색 (Full Text Search)
지금까지 우리가 작성한 쿼리는 노드의 속성값이 정확히 일치하는 경우만 검색했다.
하지만 책의 목차를 보고 원하는 내용을 빠르게 찾듯이, 노드 내부 속성의 텍스트 전체를 검색하는 인덱스를 만들 수 있다.
이렇게 하려면 먼저 인덱스를 생성해야 한다!
▪️ 전체 텍스트 인덱스 생성 예시
CALL db.index.fulltext.createNodeIndex(
'search',
['Officer', 'Intermediary', 'Address', 'Entity'],
['name', 'address']
)
▫️ search : 인덱스 이름
▫️두 번째 리스트 : 인덱스 대상 노드 라벨
▫️세 번째 리스트 : 인덱싱할 속성
위 코드를 실행하면, 지정된 라벨/속성 조합으로 전체 텍스트 인덱스가 생성된다.
▪️ 텍스트 검색 예시
인덱스를 생성한 후에는, 해당 인덱스를 활용해 속성값에 포함된 텍스트를 빠르게 검색할 수 있다.
CALL db.index.fulltext.queryNodes('search', 'Nike', {limit:10})
▫️ 인덱스 이름 : 'search'
▫️ 검색어 : 'Nike'
▫️ 결과 수 제한 : 10개
따라서 이 쿼리는 'name' 또는 'address' 속성에 'Nike'라는 단어가 포함된 모든 노드를 최대 10개까지 반환한다.
▪️ 전체 텍스트 검색 - 심화
검색을 할 때 특정 속성만 가지고 검색을 하도록 제한을 할 수도 있다.
예를 들어, Appleby라는 역외 서비스 제공업체(intermediary)에 의해 설립된 법인(Entity)을 찾고 싶다면..
CALL db.index.fulltext.queryNodes('search', 'name:"Appleby"', {limit:10})
▪️ 그래프 패턴과 함께하는 Full Text Search
이전에는 노드 속성값을 기준으로만 검색했지만, 텍스트 검색을 그래프 패턴 쿼리와 결합하면 훨씬 더 강력한 검색이 가능하다.
예를 들어, New York이라는 단어가 포함된 주소를 먼저 검색하고, 그 주소에 등록된 법인을 찾는 식의 연결형 질의가 가능하다.
▫️ 예시 1 : 'New York'이 포함된 주소 - 관련된 법인 찾기
CALL db.index.fulltext.queryNodes("search", 'address:"New York"')
YIELD node AS addr
WHERE addr.sourceID STARTS WITH "Paradise Papers"
MATCH (addr:Address)<-[:registered_address]-(entity)
RETURN addr, entity
LIMIT 50
여기서 YIELD를 사용하지 않으면 CALL 한 결과를 MATCH에서 직접 사용할 수가 없다.
CALL db.index.fulltext.queryNodes() 함수는 내부적으로 여러 노드를 반환하는데, 반환 형식은 변수명 없이 나온다.
그래서 그 결과를 쿼리 안에서 사용하려면, 반드시 YIELD로 변수에 명시적으로 이름을 붙여줘야 한다.
▫️ 예시 2 : 철자 오류 대응 - Fuzzy Matching (유사어 매칭)
틸드 기호 (~) : 데이터에 오타나 철자 변형이 있을 수 있는 것을 고려하여, 유사한 텍스트도 포함시키는 기호
CALL db.index.fulltext.queryNodes("search", 'address:Malta~')
YIELD node AS addr
WHERE addr.sourceID STARTS WITH "Paradise Papers"
MATCH (addr:Address)<-[:registered_address]-(entity)
RETURN addr, entity
LIMIT 50
'Maltta', 'Melta'와 같이 약간 오타가 있어도 검색이 가능해진다.
▫️ 예시 3 : 복합 조건 검색 - 단어 2개를 모두 포함
+속성:단어 : 해당 단어가 반드시 포함된 노드만 반환 (AND 조건)
어떤 주소는 Barcelona가 포함되어 있지만 스페인이 아닌 경우도 있다. Barcelona 그리고 Spain이라는 단어가 모두 포함된 노드만 찾고 싶을 때는, +name:Barcelona +name:Spain이라고 함으로써 name 속성에 Barcelona도 있고 Sapin도 있는 노드만 반환할 수 있다.
CALL db.index.fulltext.queryNodes("search", '+name:Barcelona +name:Spain')
YIELD node AS addr
WHERE addr.sourceID STARTS WITH "Paradise Papers"
MATCH (addr:Address)<-[:registered_address]-(entity)
RETURN addr, entity
LIMIT 50
🔹 그래프 분석 (Graph Analytics)
PageRank는 원래 google이 검색 결과에서 웹사이트의중요도를 평가하기 위해 개발한 알고리즘이다.
이 알고리즘은 중요한 엔티티는 더 많은 연결(링크)을 가지고 있으며, 직접적일 수도 간접적일 수도 있다고 가정한다.
이 알고리즘은 네트워크에서 노드의 중요도(중앙성)를 측정하는 데도 사용된다.
▪️ 예제 1 : 데이터셋에서 PageRank 상위 20개 법인 찾기
CALL gds.pageRank.stream({
nodeProjection: '*',
relationshipProjection: '*'
})
YIELD nodeId, score
WITH gds.util.asNode(nodeId) AS node, score
WHERE node:Entity AND node.sourceID STARTS WITH "Paradise Papers"
RETURN node.name AS enttiy, score
ORDER BY score DESC
LIMIT 20
- gds.util.asNode(nodeId) : nodeId를 실제 노드로 변환
- WHERE node:Entity : 결과 중 Entity 노드만 필터링
▪️ 예제 2 : PageRank 기준 상위 주소 10개 → 등록된 법인 수 확인
CALL gds.pageRank.stream({
nodeProjection: '*',
relationshipProjection: '*'
})
YIELD nodeId, score
WITH gds.util.asNode(nodeID) AS node, score
WHERE node:Address AND node.sourceID STARTS WITH "Paradise Papers"
WITH * ORDER BY score DESC LIMIT 10
MATCH (address)>-[:registered_address]-(e:Entity)
RETURN address.address, count(e) AS count
ORDER BY count DESC
'Work > GraphDB' 카테고리의 다른 글
| GraphDB를 활용한 자연어질의 처리 with LLM (0) | 2025.05.19 |
|---|---|
| [Neo4j Sandbox Data 활용 3] OpenStreetMap 데이터 활용하기 (0) | 2025.05.07 |
| [Neo4j Sandbox Data 활용 2] Graph Data Science 데이터 활용하기 (0) | 2025.04.29 |
| [Neo4j Sandbox Data 활용 1] Movie 데이터로 영화추천시스템 만들기 (0) | 2025.04.28 |
| [Youtube] Screencast: Graph Visualization With Neo4j Using Neovis.js (0) | 2025.04.28 |