📌 전체 데이터 파악
CALL db.schema.visualization

이 샘플 데이터는 airplane routes에 관한 데이터로
5개의 노드 레이블 (Airport, City, Country, Continent, Region)이 있고
5개의 관계 타입 (:HAS_ROUTE, :IN_CITY, :IN_COUNTRY, :IN_REGION, :ON_CONTINENT)이 있다.
이 데이터를 활용해서 만들 수 있는 시스템으로는
▪️ 항공 노선 추천 시스템
▪️ 최단 경로/최소 경유 비행기 경로 탐색기
▪️ 대륙/국가 기반 항공 네트워크 분석
▪️ 탐색형 지도 서비스
▪️ 항공권 가격 예측 (비행 시간, 거리, 가격 데이터를 추가로 넣어야 함)
가 있을 것 같다.
▶ 최단 경로/최소 경유 비행기 경로 탐색기는
HAS_ROUTE 관계를 따라 다익스트라 알고리즘이나 A* 알고리즘을 활용해 a에서 b까지 최소 경유지 경로 찾기 같은걸 구현할 수 있다.
neo4j에는 ShortestPath 기능도 내장돼 있어서 쉽게 할 수 있다고 한다.
▶ 대륙/국가 기반 항공 네트워크 분석은
유럽 대륙 안에서 가장 많이 연결된 공항은?
어떤 region이 가장 공항 수가 많은가?
등을 볼 수 있을 것이고~
▶ 탐색형 지도 서비스는
city → country → continent 경로를 따라 올라가거나 내려가면서
특정 공항이나 도시를 클릭하면 연결된 도시/국가를 탐색할 수 있는 탐색형 앱을 만들 수 있다.
✏️ EDA
🔻 노드 간의 관계 파악하기
MATCH (a:Airport) RETURN a LIMIT 10

🔻대륙마다 몇개의 공항이 있는지
MATCH (:Airport)-[r:ON_CONTINENT]->(c:Continent)
RETURN c.name AS continentName, count(*) AS numAirports
ORDER BY numAirports DESC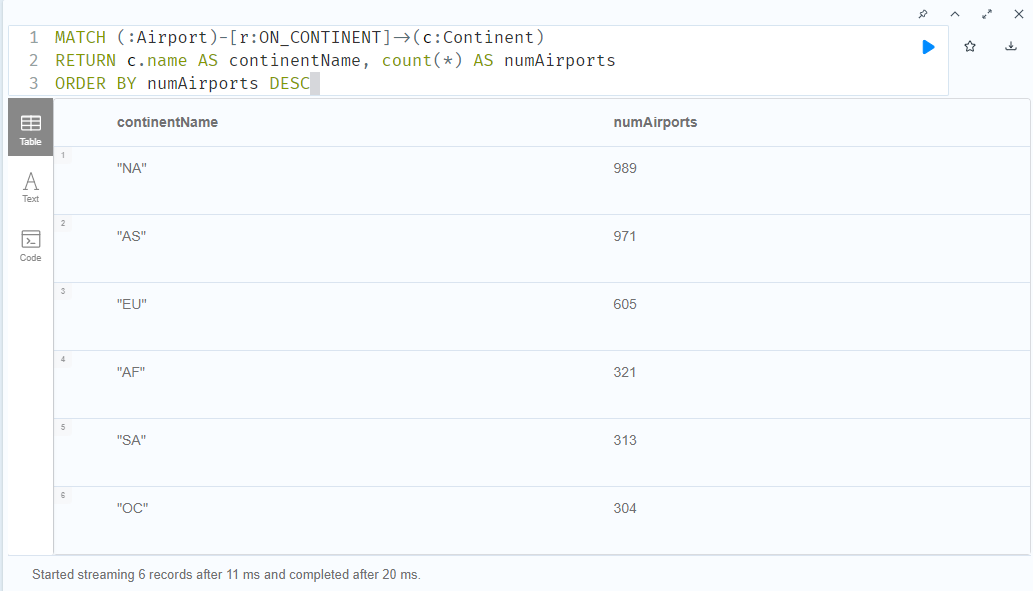
🔻 각 공항에서 출발하는 항공편 수의 최소값, 최대값, 평균, 표준편차
MATCH (deviate:Airport)-[r:HAS_ROUTE]->(arrive:Airport)
WITH deviate, count(*) as routeNo
RETURN min(routeNo), max(routeNo), avg(routeNo), stdev(routeNo)

🔻 공항 사이의 운행 거리 통계
MATCH (:Airport)-[r:HAS_ROUTE]->(:Airport)
WITH r.distance AS routeDistance
RETURN min(routeDistance), max(routeDistance), avg(routeDistance), stdev(routeDistance)

✏️ Graph Creation
GDS 알고리즘을 실행하기 위해 필요한 첫 번째 스탭은
유저가 정의한 이름 아래 graph projection을 만드는 것이다. (in-memory 그래프라고도 불린다)
그래프 카타로그에 유저가 정의한 이름 아래 저장된 graph projections은
GDS 알고리즘을 통해 결과를 계산할 때 사용되기 위해 만들어진 전체 그래프의 subsets이다!
GDS가 빠르고 효율적으로 계산을 통해 작동되도록 도와준다.
이러한 projections을 만들면 다음과 같은 방향으로 그래프 요소의 본질이 바뀔 수 있다 :
▪️관계의 방향
▪️노드 labels과 relationship types의 이름
▪️병렬 관계 집계
이 섹션에서는 네이티브 프로젝션 방식을 사용하여 그래프를 생성하는 방법을 살펴본다고 한다.
Cypher 프로젝션을 통해 그래프를 생성할 수도 있지만, 이는 이 가이드의 범위를 벗어나서 안하는 듯!
📌 Graph Catalog : creating a graph with native projections
네이티브 프로젝션은 그래프 프로젝션을 생성할 때 가장 빠른 성능을 제공한다.
이 방법은 세 가지 필수 매개변수 — graphName, nodeProjection, relationshipProjection — 를 필요로 한다.
또한 그래프를 추가로 설정할 수 있도록 선택적인 구성 매개변수들도 사용할 수 있다.
일반적으로 네이티브 프로젝션을 생성하는 문법은 다음과 같다.
CALL gds.graph.project(
graphName: String,
nodeProjection: String or List or Map,
realtionshipProjection: String or List or Map,
configuration: Map
)
YIELD
graphName: String,
nodeProjection: Map,
nodeCount: Integer,
relationshipProjection: Map,
relationshipCount: Integer,
projectMillis: Integer
이 데이터셋으로는.. 모든 공항 사이의 경로(routes)의 graph projection을 만들 수 있다.
CALL gds.graph.project(
'routes',
'Airport',
'HAS_ROUTE'
)
YIELD
graphName,
nodeProjection,
nodeCount,
relationshipProjection,
relationshipCount
📌 Graph Catalog : listing and existence
어떤 그래프가 카타로그에 있고 그들의 속성이 무엇인지 아는 것은 도움이 될 수 있다.
모든 그래프를 보기 위해서는
CALL gds.graph.list()
각각의 그래프를 확인할 수도 있는데, 예를 들어 routes 그래프를 보려고 한다면 :
CALL gds.graph.list('routes')
✏️ Algorithm syntax
이름이 있는 graph projection을 만들고 나면, 각 production tier 알고리즘마다 4가지 실행 모드를 사용할 수 있다
▪️stream
▫️알고리즘의 결과를 데이터베이스를 변경하지 않고 레코드 스트림 형태로 반환한다.
▪️write
▫️알고리즘의 결과를 Neo4j 데이터베이스에 기록하고, 요약 통계 정보를 담은 단일 레코드를 반환한다.
▪️mutate
▫️알고리즘의 결과를 프로젝션된 그래프에 기록하고, 요약 통계 정보를 담은 단일 레코드를 반환한다.
▪️stats
▫️요약 통계 정보를 담은 단일 레코드만 반환하며, Neo4j 데이터베이스나 프로젝션된 그래프에는 어떤 변경도 하지 않는다.
🔸추가 옵션 : estimate
위의 4가지 모드 외에도, estimate 모드를 사용하면 특정 알고리즘이 얼마나 많은 메모리를 사용할지 예측할 수 있다.
🔻mutate에 대한 special explanation
feature engineering을 수행할 때는 GDS 알고리즘을 통해 계산된 값을 그래프 프로젝션에 포함하고 싶어질 수 있다.
이럴 때 mutate 모드를 사용한다.
- 이 모드는 실제 데이터베이스는 변경하지 않으며,
- 계산된 값을 프로젝션된 그래프의 각 노드에 기록하여 이후 계산에 활용할 수 있게 한다.
따라서 복잡한 그래프 알고리즘이나 파이프라인을 사용할 때 매우 유용하다~!
GDS API 문서를 확인하도록...
일반적인 알고리즘의 사용
CALL gds[.<tier>].<algorithm>.<execution-mode>[.<estimate>](
graphName: String,
configuration: Map
)
[] 안의 항목은 선택 사항이다.
<tier>는 (존재할 경우) 해당 알고리즘이 알파(alpha) 또는 베타(beta) 단계에 있는지를 나타낸다.
프로덕션 티어(production tier) 알고리즘에는 <tier>가 사용되지 않는다...
<algorithm>은 알고리즘의 이름이고, <execution-mode>는 앞서언급한 4가지 실행 모드 중 하나다.
<estimate>는 선택적 플래그로, 메모리 사용량의 추정치를 반환할지를 나타낸다.
✏️ PageRank를 통한 중심성 측정
중심성(Centrality) 또는 노드의 중요도를 판단하는 방법은 여러가지 있지만, 가장 널리 사용되는 방법 중 하나는 PageRank 계산이다.
(이전의 포스트에서 다룬 내용 : https://raeul0304.tistory.com/3)

PageRank는 노드의 전이적(또는 방향성 있는) 영향력을 측정한다.
이 접근법의 장점은, 해당 노드의 이웃 노드들이 가지는 영향력을 활용하여 대상 노드의 중요도를 판단한다는 점이다.
핵심 개념은 다음과 같다 :
더 많은 수의 링크를 가지고 있고, 더 영향력 있는 노드들로부터 링크를 받는 노드는 더 중요하다고 간주되며, 이는 더 높은 PageRank 점수로 이어진다.
PageRank는 반복 기반(iterative) 알고리즘이다.
반복 횟수는 GDS 내에서 설정 가능한 매개변수이고, 알고리즘은 노드 점수가 지정된 허용 오차(tolerance) 내에서 수렴하면 중간에 종료될 수도 있다. 이 허용 오차 역시 GDS에서 구성 가능하다고 한다.
📍PageRank : stream mode
위에서 언급한 바와 같이, stream 모드는 데이터베이스나 graph projection을 변경하지 않고 계산 결과를 보여준다.
CALL gds.pageRank.stream('routes')
YIELD nodeID, score
WITH gds.util.asNode(nodeId) AS n, score AS pageRank
RETURN n.iata AS iata, n.descr AS description, pageRank
ORDER BY pageRank DESC, iata ASC
이 쿼리는 PageRank 점수 기준으로 내림차순 정렬된 공학 목록을 출력한다.
▪️YIELD : Cypher 쿼리에서 프로시저나 함수의 실행 결과로부터 특정 컬럼(속성)을 추출할 때 사용하는 키워드
▫️CALL 구문은Neo4j에서 프로시저나 함수를 호출할 때 사용되고, CALL로 호출된 함수에서 YIELD는 출력 컬럼들 중에 어떤 것들을 사용할지 지정한다. 위 구문에서는 nodeId와 score만 가져온 것!
▪️.asNode() : 노드 객체로 변환할 때 사용
▫️nodeId는 내부 ID이므로, gs.util.asNode(nodeID)로 실제 노드 객체로 변환한 것!
YIELD랑 MATCH의 차이가 명확하게 그려지지 않아서 정리를 해보았다.
🔸MATCH
- 그래프 패턴을 기반으로 데이터를 조회할 때 사용한다.
- 노드나 관계의 구조적 연결(패턴)을 지정하고, 해당 조건을 만족하는 데이터를 가져온다.
- SQL의 SELECT...FROM...WHERE... 에 가까운 역할을 한다.
🔸YIELD
- 프로시저 호출 결과 중 필요한 값만 선택적으로 가져올 때 사용한다
- SQL의 SELECT나 Python의 return value1, value2와 유사한 개념이다.
- 만약 프로시저가 반환하는 전체 컬럼 목록을 보고 싶다면, YIELD * 를 사용하면 된다.
- 직접 노드를 패턴으로 찾는게 아니라, 어떤 분석이나 계산 작업의 결과를 가져오는 방식인것!!
| MATCH | CALL....YEILD | |
| 목적 | 노드/관계 탐색 | 알고리즘/프로시저 실행 결과 사용 |
| 기반 | Cypher 패턴 | 내장/확장 프로시저 |
| 예시 | 연결된 노드 찾기 | PageRank, 커뮤니티 탐지, 경로 찾기 등 |
| 결과 | 직접 매칭된 노드/관계 | 계산된 분석 결과 (점수, 집합 등) |
✨추가 정보 : 관계 가중치 (weighted relationships)
PageRank는 관계에 가중치를 부여하여 실행할 수도 있다.
예를 들어, 관계의 빈도 / 강도 / 수치형 속성 등이 있는 경우, 이 값을 기준으로 PageRank 점수를 더욱 정밀하게 계산할 수 있다.
📍PageRank : write mode
만약 PageRank 계산 결과를 그래프 각각의 노드의 속성으로 추가하고 싶으면, .write()을 사용하면 된다.
CALL gds.pageRank.write('routes',
{
writeProperty: 'pageRank'
}
)
YIELD nodePropertiesWritten, ranIterations

그런 다음, 아래와 같이 작성하여 결과를 확인할 수 있다 :
MATCH (a:Airport)
RETURN a.iata AS iata, a.descr AS description, a.pageRank AS pageRank
ORDER BY a.pageRank DESC, a.iata ASC

✏️ Community 감지 - Louvain Modularity
중심성 측정과 마찬가지로, 그래프 내에서 커뮤니티/클러스터를 식별하는 방법도 다양하게 존재한다.
커뮤니티 탐지는 그래프 내에서 밀집된 영역(군집)을 찾아내는 데 유용한 도구다.
(이 역시 이전 포스트에서 다뤘으니 참고! )
예를 들어, 공항 간의 경로를 나타낸 그래프에서는 서로 간에 많은 경로를 공유하고 있는 공항들의 자연스러운 클러스터를 커뮤니티 탐지를 통해 찾아낼 수 있다.
📌 Louvain Modularity 알고리즘
이 알고리즘은 관계의 상대적 밀도를 측정하여 그래프 내의 클러스터를 찾아낸다.
- 이 밀도는 모듈성 점수(modularity score)로 정량화된다.
- 이는 클러스터 내부의 관계 밀도를 평균 또는 임의 샘플과 비교한 값이다.
- 모듈성 점수가 높을수록 해당 클러스터는 더 밀집된 상태라고 볼 수 있다.
Louvain 방법은 이 모듈성 점수를 최대화하도록 그래프를 재귀적으로 분할하면서 클러스터를 찾아낸다.
PageRank와 마찬가지로, GDS에서는 사용자가 최대 반복 횟수와 조기 종료를 위한 허용 오차를 설정할 수 있다.
또한, 이 알고리즘은 수렴해 가는 과정 중간의 커뮤니티 할당 상태도 반환할 수 있다.
예시
CALL gds.louvain.stream('routes')
YIELD nodeId, communityId
WITH gds.util.asNode(nodeId) AS n, communityId
RETURN
communityId,
SIZE(COLLECT(n)) AS numberOfAirports,
COLLECT(DISTINCT n.city) AS cities
ORDER BY numberOfAirports DESC, communityId;
🔻 COLLECT란?
COLLECT(expr)는 집계 함수(aggregation function)중 하나로, 쿼리 결과의 여러 행들을 리스트(list) 형태로 모아주는 함수다.
▪️SQL의 GROUP_CONCAT이나 ARRAY_AGG와 비슷한 기능이다
▪️DISTINCT 키워드와 함께 쓰면 중복 제거된 리스트를 만들 수 있다
▪️COLLECT는 WITH 또는 RETURN절에서 그룹별로 리스트로 묶을 때 사용한다
따라서 위 코드에서는
- COLLECT(n) : 해당 커뮤니티에 속한 모든 노드를 리스트로 수집 → SIZE()를 사용하여 노드 수 계산 = 공항 수
- COLLECT(DISTINCT n.city)는 해당 커뮤니티에 속한 서로 다른 도시 목록을 리스트로 수집한다.
결과

결과를 보면
- 가장 큰 커뮤니티는 미국 내 공항들에 해당
- 두 번째로 큰 커뮤니티는 유럽의 공항들로 구성
- 그 이후로도 비슷한 방식으로 나뉘는 것을 확인할 수 있다.
그래프에 나타난 공항들이 대륙(continent) 기준으로 자엽스럽게 군집화된 것으로 보아 결과가 타당해보임!
결과를 노드 속성으로 저장하고 싶다면, CALL gds.louvain.write() 를 사용하면 된다!
이 함수는 각 노드에 커뮤니티 ID를 속성값으로 기록해준다.
✏️ Node Similarity (노드 유사도)
중심성이나 커뮤니티 탐지 알고리즘과 마찬가지로, 노드 간 유사도를 계산하는 방법도 여러가지가 존재한다.
일반적으로 노드 유사도는 노드 쌍(node pairs)간의 벡터 기반 메트릭(vector-based metric)을 통해 계산된다.
이러한 방식은 추천시스템 등에 유용하게 사용된다. 고객의 이전 구매 이력을 기반으로 유사한 상품을 추천하는 경우가 대표적!
이 포스트에서는 GDS에서 제공하는 Node Similarity 알고리즘을 사용한다.
이 알고리즘은 자카드 유사도(Jaccard Similartiy)라는 일반적인 접근법을 기반으로 한다.
🔻Jaccard 기반 노드 유사도란?
Jaccard 유사도는 두 노드가 공유하는 이웃 노드의 수를 기반으로 한다
- 이웃 노드(neighbor) : outbound relationship로 연결된 다른 노드를 의미
- 간단히 말하면, 두 노드가 공유하는 이웃의 비율이 높을수록 유사도도 높아진다.
- 유사도 값은 다음과 같은 범위를 가진다
> 0 : 공통 이웃 없음 (완전한 비유사)
> 1 : 이웃이 전부 동일함 (완전한 유사)
🔻성능 주의사항 및 최적화 옵션
노드 유사도 알고리즘은 계산량이 많기 때문에, 노드 수에 따라 제곱에 비례하는 시간 복잡도(O(n²))를 가진다.
따라서 대규모 그래프에서는 실행 시간을 줄이기 위해 제한 조건(cutoffs)을 설정할 수 있다.
▫️ 노드의 degree(관계 수) 기준으로 필터링 : ex. 관계가 너무 많은 노드는 제외
▫️ 유사도 점수 기준 필터링 : ex. 유사도가 일정 값 이상인 쌍만 고려
또한, 결과 쌍의 개수를 제한할 수도 있다.
▫️ 전체 쌍 수 제한 : N
▫️ 노드당 유사도 쌍 수 제한 : K
예시를 살펴보자
CALL gds.nodeSimilarity.stream('routes')
YIELD node1, node2, similarity
WITH gds.util.asNode(node1) AS n1, gds.util.asNode(node2) AS n2, similarity
RETURN
n1.iata AS iata,
n1.city AS city,
COLLECT({iata:n2.iata, city:n2.city, similarityScore: similarity}) AS similarAirports
ORDER BY city LIMIT 20
결과를 보면 각 iata, city별로 similarAirporsts 리스트가 10개씩 출력이 되는 걸 확인할 수 있을 것이다.
이건 default가 topK=10이기 때문인데, 아래 코드처럼 topK 값을 지정할 수 있다.
CALL gds.nodeSimilarity.stream(
'routes',
{
topK: 3
}
)
YIELD node1, node2, similarity
WITH gds.util.asNode(node1) as n1, gds.util.asNode(node2) as n2, similarity
RETURN
n1.iata AS iata,
n1.city AS city,
COLLECT({iata:n2.iata, city:n2.city, similarityScore: similarity}) AS similarAirports
ORDER BY city LIMIT 20
위 예시를 보며 2가지 의문이 들었다.
첫 번째로, .asNode()가 노드 객체로 변환해준다고 했는데 문득 왜 이렇게 해야하는지 의문이 들었다.
그 이유를 살펴보자~~
🔸내부 노드 ID
Neo4j에서는 각 노드마다 자동으로 부여되는 고유한 ID값이 있다. 이것을 내부 노드 ID라고 한다.
이 ID는 노드의 속성값이 아니라, Neo4j 내부에서 노드를 관리하기 위해 사용하는 숫자형 식별자다.
GDS 알고리즘은 성능 최적화를 위해 속성 대신 이 내부ID만 사용해 계산을 수행한다.
하지만, 이런 ID를 사용하면 사람이 보기엔 의미가 없어진다.
그래서 gds.util.asNode(12)처럼 12라는 ID를 가진 실제 노드 객체 (ex. (n:Aiport {iata: "ICN"}) ) 로 바꿔주는 거다!
두 번째로.. graph projection이 sql의 VIEW 같은건가? 라는 생각이 들었다.
우선 답은 NO.
GDS에서의 graph projection은 데이터베이스에서 정의한 그래프 구조의 인메모리 버전이다.
Neo4j의 기본 데이터베이스는 일반적으로 속성 그래프로 저장되어 있다.
GDS 알고리즘을 실행하려면, 이 데이터를 GDS에서 사용할 수 있는 형태로 projection 해야한다.
Projection은 일종의 VIEW처럼 보이지만, 실제로는 메모리 위에 존재하는 구조로 다른 개념이다.
Graph Projection 개념을 다시 빠르게 recap 해보면..!
1. Graph Projection 만들기 : gds.graph.project는 데이터베이스의 노드/관계 중 일부를 메모리에 로딩해서 GDS용 그래프를 만드는 작업이다.
CALL gds.graph.project(
'routes',
'Airport',
'ROUTE'
)
이전에 이렇게 projection을 만들었었는데, routes라는 이름의 projection 그래프를 생성한 것이고
DB에 있는 'Airport' 타입의 노드들과 'ROUTE' 타입의 관계만! 포함을 시킨 것!!
더 세밀하게 속성까지 지정할 수도 있다.
CALL gds.graph.project(
'routes',
{
Airport: {
properties: ['iata', 'city']
}
},
{
ROUTE: {
properties: ['distance']
}
}
)
2. GDS 알고리즘 실행
Projection 그래프를 만든 다음에는 GDS 알고리즘을 실행하게 된다
이때 YIELD는 결과로부터 필요한 필드만 꺼내는 역할을 한다.
🔻 topK와 bottomN
▶ topK, topN
위에서 결과 쌍의 개수도 제한할 수 있다고 했는데
또한, 결과 쌍의 개수를 제한할 수도 있다.
▫️ 전체 쌍 수 제한 : N
▫️ 노드당 유사도 쌍 수 제한 : K
CALL gds.nodeSimilarity.stream(
'routes',
{
topK: 1,
topN: 10
}
)
YIELD node1, node2, similarity
WITH gds.util.asNode(node1) AS n1, gds.util.asNode(node2) as n2, similarity
RETURN
n1.iata AS iata,
n1.city AS city,
{iata: n2.iata, city: n2.city} AS similarAirport,
similarityScore
ORDER BY city
- topK: 1 → 각 공항 노드에 대해 가장 유사한 공항 하나만 선택
- topN: 10 → 전체 그래프에서 유사도 점수가 가장 높은 10쌍만 반환
즉, 각 노드에서 최고 유사도를 구한 뒤, 전체 중 가장 유사한 10쌍을 보여주는 쿼리다.
이해가 퐉! 되시나요?
(전 안됨)
| 항목 | topK | topN |
| 기준 | 각 노드별 | 전체 그래프 기준 |
| 의미 | 각 노드에 대해 유사한 노드 K개 선택 | 그래프 전체에서 유사도 높은 N쌍 선택 |
| 제한 방식 | 노드마다 K개씩 (즉, 100개 노드면 최대 100×K개 쌍) | 가장 유사한 N쌍만 전역에서 추림 |
| 예시 | 공항 A의 가장 유사한 공항 3개 | 전체 공항 중 유사도가 가장 높은 10쌍 |
| 사용 시점 | 노드 중심 분석 (ex. 유사 추천) | 상위 유사 쌍 분석 (ex. 최상위 유사 관계만 보고 싶을 때) |
다른 예시를 들어보면, 공항 5개가 있을 때 (A, B, C, D, E)
- topK: 2
→ 각 공항에 대해 유사한 공항 2개씩 반환
→ 총 5 × 2 = 최대 10쌍 - topN: 3
→ 전체 그래프에서 유사도 점수가 가장 높은 3쌍만 반환
→ 전역적으로 상위 3쌍만 남음 - 둘 다 쓰면? topK: 2, topN: 3
→ 각 노드당 2쌍씩 계산하되, 최종 출력은 그중 유사도 가장 높은 3쌍만 출력
▶ bottomN
반대로, bottomN을 지정하면 그래프 전체에서 유사도 점수가 가장 낮은 쌍들을 추출할 수 있다
- 이 기능은 다른 노드들과 거의 유사하지 않은 노드를 찾고 싶을 때 유용하다
- 예를 들어 외딴 지역의 공항이나 특이한 연결 구조를 가진 노드를 식별하는 데 활용할 수 있다.
🔻degree and similarity cutoff
노드 유사도 계산 시, 불필요한 계산을 줄이고 성능을 향상시키기 위해 다음과 같은 제한 조건(cutoff)을 설정할 수 있다.
📍 degreeCutoff : 최소 연결 수 제한
degreeCutoff는 노드가 유사도 계산 대상이 되기 위한 최소 연결 수(관계 수)를 의미한다.
예를 들어,
CALL gds.nodeSimilarity.stream(
'routes',
{
degreeCutoff: 100
}
)
YIELD node1, node2, similarity
WITH gds.util.asNode(node1) AS n1, gds.util.asNode(node2) AS n2, similarity
RETURN
n1.iata AS iata,
n1.city AS city,
COLLECT({
iata: n2.iata,
city: n2.city,
similarityScore: similarity
}) AS similarAirports
ORDER BY city
LIMIT 20
이 경우, 하나의 공항이 100개 이상의 연결을 가지고 있어야만 유사도 계산에 포함된다.
이런 설정은 노드 수가 많고 연결 밀도가 고르지 않은 그래프에서 매우 유용하다.
📍 similarityCutoff: 유사도 점수 제한
similarityCutoff는 유사도 점수가 일정 값 이상인 경우에만 결과로 포함되게 한다.
예를 들어~
CALL gds.nodeSimilarity.stream(
'routes',
{
similarityCutoff: 0.5
}
)
YIELD node1, node2, similarity
WITH gds.util.asNode(node1) AS n1, gds.util.asNode(node2) AS n2, similarity
RETURN
이하 동일
이러면 유사도 점수가 0.5 이상인 노드 쌍만 반환한다.
이런 설정은 결과값이 너무 많아질 때 의미 있는 유사성만 보고 싶을 때 유용하다!
✏️ 경로 탐색 Path Finding
일반적으로, 경로 탐색의 목적은 두 개 이상의 노드 사이에서 최단 경로를 찾는 것이다.
예를 들어, 우리가 사용 중인 공항 경로 그래프에서는 이 알고리즘을 활용해
전체 비행 거리(total flight distance)를 최소화하는 공항 연결 경로를 찾을 수 있다.
이 포스트에서는 가장 널리 사용되는 '다익스트라 알고리즘'을 사용하여 두 노드 사이의 최단 경로를 찾는 방법을 다룰 것이다.
🔻가중치 graph projection 만들기
이전 예시들에서는 공항 간의 경로(route) 거리를 고려하지 않았다.
하지만 이번에는 다익스트라 알고리즘에서 경로 거리를 가중치로 사용해서, 최종 최단 경로가 실제 물리적 거리 기준으로 계산되도록 할 것이다.
이를 위해서는 그래프 프로젝션에 route 거리 정보를 관계 속성으로 포함해야 한다:
CALL gds.graph.project(
'routes-weighted',
'Airport',
'HAS_ROUTE',
{
relationshipProperties: 'distance'
}
) YIELD graphName, nodeProjection, nodeCount, relationshipProjection, relationshipCount
YIELD를 할 때 작성하는 필드명은 다 정해져있고 프로시저별로 명확하게 나뉘어져 있다고 한다.
GDS 문서에서 확인 가능하다고 하니, 사용하고자 하는 프로시저마다 확인해서 사용하면 될 것 같다.
간단하게 살펴보면...
| 프로시저 | 주요 YIELD 필드 |
| gds.graph.project | graphName, nodeCount, relationshipCount, nodeProjection 등 |
| gds.pageRank.stream | nodeId, score |
| gds.louvain.stream | nodeId, communityId |
| gds.nodeSimilarity.stream | node1, node2, similarity |
| gds.graph.list() | graphName, nodeCount, creationTime, schema |
Neo4j에서는 .help()를 통해 직접 확인할 수 있는 방법도 제공한다:
CALL gds.help('pagerank')
CALL gds.help('nodeSimilarity.stream')
🔻다익스트라 알고리즘 Dijkstra's algorithm
가중치 그래프 프로젝션을 활용해 덴버 국제공항(DEN)에서 말레 국제공항(MLE)까지의 최단 거리를 계산해보자
MATCH (source:Airport {iata: 'DEN'}), (target:Airport {iata: 'MLE'})
CALL gds.shortestPath.dijkstra.stream('routes-weighted', {
sourceNode: source,
targetNode: target,
relationshipWeightProperty: 'distance'
})
YIELD index, sourceNode, targetNode, totalCost, nodeIds, costs, path
RETURN
index,
gds.util.asNode(sourceNode).iata as sourceNodeName,
gds.util.asNode(targetNode).iata as targetNodeName,
totalCost,
[nodeId IN nodeIds | gds.util.asNode(nodeId).iata] AS nodeNames,
costs,
nodes(path) AS path
ORDER BY index

위 쿼리를 보면, '출발 노드(source)'와 '도착 노드(target)'를 지정하고, 관계 가중치로 'distance' 속성을 사용하고 있다.
이 쿼리를 통해 다음과 같은 정보들이 반환된다:
▪️최단 거리 총합(totalCost) : 거리 기반 비용으로, 일반적으로 두 노드 간의 직선 거리를 의미
▪️경유한 공항들의 목록 (nodeNames) : 경로를 따라 연결된 공항들의 IATA 코드 리스트
▪️ index : 쿼리 결과 순서
▪️ sourceNode, targetNode : 내부 노드 ID
▪️ nodeIds : 경로에 포함된 모든 노드의 내부 ID 목록
▪️각 엣지의 거리 비용(costs)과 실제 경로(path 객체)도 함께 반환
이 예시에서는, 위 결과 그림과 같이 최단 경로가 총 4번의 이동(hop)을 거치는 경로라는 것을 확인할 수 있다.
실제 운항에서는 이상적이지는 않을 수 있지만~ 전체 거리 기준으로는 최소화된 경로다!
다른 relationshipWeightProperty를 쓰고 싶다면, flight_time, cost 같은 속성도 사용할 수 있다.
relationshipWeightProperty에 들어가는 값은 내가 projection 만들 때 포함한 관계 속성 이름이기 때문에,
graph projection 생성 시 포함한 속성들을 모두 활용 가능~!
RETURN문을 살펴보면 새롭게 보이는 구문들이 있어 정리를 하고 가겠다...
🔸nodes()
nodes()는 Cypher에서 제공하는 내장 함수 중 하나로, 경로(Path)를 입력받아 그 경로에 포함된 모든 노드들을 순서대로 반환한다.
▪️ 오직 Path 타입의 값에만 사용할 수 있음
▪️ 경로(Path) 객체로부터 노드 정보를 추출할 때 사용
▫️ 경로 기반 검색, 경로 시각화, 그래프 알고리즘 결과 후처리 등에서 광범위하게 사용됨
▪️ 반환 타입 : List<Node>
▪️ 입력 조건 : 반드시 Path 타입 - (MATCH ... = p 또는 GDS YIELD path 등)
주요 용도를 예시와 함께 살펴보자!
📍 경로 기반 분석 및 시각화
경로 상에 어떤 노드들이 등장하는지 추출할 때 사용한다
#a에서 b로 가는 최대 3단계 친구 관계의 경로에서 거치는 모든 사람 노드 추출
MATCH p = (a)-[:FRIEND*..3]->(b)
RETURN nodes(p) AS friendsAlongTheWay
📍 GDS 알고리즘 후처리
GDS 알고리즘 (예: Dijkstra, Yen, AllShortestPaths 등)의 YIELD path 결과로부터 노드를 추출할 때 사용한다
#GDS가 계산한 최단 경로의 노드 리스트 확인
CALL gds.shortestPath.dijkstra.stream(...)
YIELD path
RETURN nodes(path) AS shortestPathNodes
📍노드 속성 추출 및 변환
nodes() 결과를 기반으로 속성 매핑 또는 필터링을 할 수 있다.
#각 노드의 name 속성만 추출
RETURN [n IN nodes(path) | n.name] AS namesAlongPath
📍조건 필터링
경로에 특정 속성의 노드가 포함되는지를 확인하는데 사용한다.
#경로 상에 'BLOCKED' 상태인 노드가 있는 경로만 필터링
WITH nodes(p) AS pathNodes
WHERE ANY(n IN pathNodes WHERE n.status = 'BLOCKED')
RETURN p
자주 쓰이는 다른 함수들로는!
| 목적 | 함수 |
| ID → 노드 | gds.util.asNode(nodeId) |
| 관계에서 시작/끝 노드 | startNode(rel), endNode(rel) |
| 경로에서 관계 추출 | relationships(path) |
| 경로 길이 | length(path) |
🔸list comprehension
기본 문법
[variable IN list | expression]
▪️ variable : 리스트 내 각 요소를 받을 변수
▪️ list : 순회할 원본 리스트
▪️ expression : 각 요소에 대해 적용할 표현식
결과는 expression을 적용한 새로운 리스트가 되는 것이다! 약간 람다 함수처럼 되네..
예시로~
RETURN [x IN [1,2,3] | x] AS copy 라고 하면 결과는 [1,2,3]이 되고
RETURN [x IN [1,2,3] | x*2] AS doubled 라고 하면 결과는 [2,4,6] 이 되는 것!!
다른 예시로는...
MATCH (a:Airport)
WITH collect(a) AS airports
RETURN [n IN airports | n.iata] AS iataCodes공항 노드들의 iata 속성만 뽑아 리스트로 만든 것이고..
RETURN [x IN [1,2,3,4,5] WHERE x % 2 = 0 | x * 10] AS evensTimesTenWHERE로 필터 조건을 걸어 사용한 예제다!
끝으로 메모리를 비우는 작업이 필요하다! 사용하지 않는 graph projections을 꼭 지우자~~
CALL gds.graph.drop('routes');
CALL gds.graph.drop('routes-weighted');'Work > GraphDB' 카테고리의 다른 글
| [Neo4j Sandbox Data 활용 4] ICIJ OffShoreleaks (0) | 2025.05.19 |
|---|---|
| [Neo4j Sandbox Data 활용 3] OpenStreetMap 데이터 활용하기 (0) | 2025.05.07 |
| [Neo4j Sandbox Data 활용 1] Movie 데이터로 영화추천시스템 만들기 (0) | 2025.04.28 |
| [Youtube] Screencast: Graph Visualization With Neo4j Using Neovis.js (0) | 2025.04.28 |
| Neo4j Cypher 구문 기본 - [Youtube] Neo4j (Graph Database) Crash Course (0) | 2025.04.24 |